- Italia
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Programmazione FPGA Xilinx e flusso di design Vivado spiegati
Catalogo

Esplorare i tutorial FPGA Xilinx
Lavorare con gli FPGA può sembrare mentalmente più gravoso rispetto al software all'inizio, in parte perché l'obiettivo non è eseguire istruzioni ma descrivere strutture hardware che funzionano allo stesso tempo. Si finisce per pensare alla concorrenza, alle regole di clock, al comportamento di reset e se i rapporti temporali concordano con ciò che si crede di aver costruito. Quando le persone si frustrano presto, spesso non è perché mancano di impegno, ma perché troppe parti mobili cambiano tra i tentativi e la causa del fallimento diventa fastidiosamente sfuggente.
Un modo costante per andare avanti è ripetere lo stesso flusso di lavoro fino a quando diventa abbastanza familiare da far risaltare gli errori. Tieni una scheda Xilinx ben supportata sulla tua scrivania, inizia con un piccolo design HDL, simula finché le forme d'onda hanno senso, esegui sintesi e implementazione in Vivado, programma il dispositivo e poi conferma il comportamento sui pin reali. Anche se questo processo può sembrare ripetitivo, aiuta a ridurre l'incertezza su se un problema sia causato dal codice di design, dai vincoli o dalla configurazione della scheda, rendendo il debug più efficiente.
Nello studio quotidiano, la parte ripida della curva di apprendimento si concentra solitamente attorno a poche competenze che si rafforzano a vicenda: usare il flusso di Vivado con disciplina, scrivere Verilog sintetizzabile che rispecchi come ti aspetti e fare debug degli inevitabili divari tra simulazione e scheda fisica con un metodo di cui ti fidi. Se tratti ciascuna costruzione come un esperimento controllato, cambi una variabile, osservi l'effetto e annoti ciò che hai visto, noterai di trascorrere meno tempo a indovinare e più tempo a formare istinti affidabili.
Usa il flusso di progetto di Vivado in un modo che rimanga stabile nel tempo
Vivado si comporta meno come un semplice pulsante di compilazione e più come una pipeline che trasforma RTL in un design posizionato e instradato che deve vivere entro le realtà elettriche e temporali della scheda. Molti principianti scoprono, a volte nel modo più difficile, che molta correttezza risiede al di fuori dell'HDL: vincoli, definizioni di clock, standard I/O e impostazioni degli strumenti possono silenziosamente decidere se l'hardware si comporta come la simulazione prometteva.
Un flusso pulito inizia mantenendo la configurazione del progetto modesta e ripetibile, in modo da poter capire quando hai davvero migliorato il design rispetto a quando hai accidentalmente cambiato l'ambiente.
Scegli una scheda supportata e rimani con essa abbastanza a lungo da costruire un'intuizione che puoi riutilizzare. Le schede con documentazione solida e progetti di riferimento tendono a ridurre l'ansia di fondo, perché puoi controllare il tuo pinout, i clock e le assunzioni di potenza senza cercare post non ufficiali nei forum.
Inizia con un modulo principale che produca un risultato visibile rapidamente. Quel feedback immediato ti aiuta a convalidare che il clock sta funzionando, i pin sono mappati correttamente e i bitstream vengono generati nel modo in cui pensi.
Esempi di comportamento osservabile a livello superiore:
• Un LED lampeggiante
• Un'eco UART
• Un contatore che guida GPIO
Una pratica utile è standardizzare un piccolo modello di alto livello all'inizio. Ad esempio, mantieni un ingresso orario, un approccio di reset che comprendi e un piccolo pacchetto GPIO coerente. Quando l'impalcatura rimane la stessa da progetto a progetto, puoi concentrare la tua attenzione sulla nuova logica invece di dover ridefinire i fondamenti ogni volta, qualcosa che può sembrare noioso e sorprendentemente soggetto a errori.
Le restrizioni sono una parte fondamentale del design FPGA piuttosto che un passo finale di aggiustamento. Molti problemi hardware iniziali si verificano anche quando il design RTL è corretto perché mancano o sono errate le restrizioni temporali, i pin sono assegnati in modo improprio, o gli standard I/O non corrispondono ai requisiti reali della scheda.
Un flusso di lavoro concreto che ti mantiene onesto è definire i clock in XDC, mappare le porte utilizzando il master XDC del fornitore come riferimento, e poi verificare gli standard I/O rispetto allo schema della scheda. Quel processo può sembrare un po' burocratico all'inizio, ma tende a sostituire il sospetto vago con fatti verificabili.
La chiusura temporale non è riservata solo ai design rapidi. Anche la logica che sembra lenta sulla carta può comportarsi male se lo strumento deduce relazioni di clock indesiderate o se i segnali asincroni vengono gestiti in modo superficiale. Abituarsi a leggere i report temporali all'inizio può ridurre quella sensazione sgradevole di "Spero che vada tutto bene" quando i design diventano più grandi.
Vivado ti dice costantemente cosa pensa del tuo design; la parte dolorosa è che è facile cliccare oltre gli avvisi e poi passare ore a fare debug di un problema già descritto sulla console. Nel tempo, le persone che si muovono più velocemente sono spesso quelle che creano un'abitudine calma di controllare i report dopo ogni esecuzione, anche quando si aspettano che tutto sia a posto.
Dopo ogni esecuzione di sintesi/implementazione, mantieni queste categorie di report insieme nella loro linea di checklist:
• Stato temporale e percorsi critici
• Utilizzo delle risorse (LUT/FF/BRAM/DSP) rispetto alle aspettative
• Risultati di inferenza (per RAM, blocchi DSP e altre strutture intese)
Quando un avviso è presente fin dalla prima build, tende a continuare a comparire nei fallimenti più strani in seguito. Una postura produttiva è assumere che gli avvisi meritino attenzione finché non puoi spiegare, in termini ingegneristici semplici, perché sono benigni per il tuo design specifico.
Scrivi Verilog sintetizzabile che si mappa pulitamente sull'hardware FPGA
Il lavoro HDL è più vicino al design dei circuiti che allo sviluppo di app, e quel cambiamento può essere emotivamente scioccante: puoi scrivere Verilog valido che simula splendidamente, ma si sintetizza in qualcosa di più lento, più grande o semplicemente diverso da come l'avevi immaginato. L'obiettivo è descrivere strutture che l'FPGA può implementare in modo prevedibile: flip-flop, logica LUT, BRAM e blocchi DSP, in modo che il comportamento e i tempi si allineino con la tua intenzione.
Quando il mapping è prevedibile, il debug sembra meno come un dibattito con lo strumento e più come un affinamento di un design.
Una base confortevole per molti principianti è un singolo dominio di clock con logica sincrona semplice. Utilizza blocchi sempre clocked per stati sequenziali e assegnazioni continue (o blocchi combinatori scritti correttamente) per percorsi combinatori. Creare logica "simile a un clock" nel tessuto può funzionare in casi particolari, ma tende a invitare a rischi di dominio di clock a meno che tu non comprenda già l'illuminazione del clock, il routing e le implicazioni temporali.
Il comportamento di reset è un altro posto in cui piccole scelte possono creare risultati della scheda sorprendentemente incoerenti. I reset asincroni possono essere utili, ma possono anche produrre pericoli di deassertione o sensibilità a differenze di alimentazione a livello di scheda. Molti design FPGA utilizzano reset completamente sincroni o affermazioni asincrone con rilascio sincrono perché questi approcci aiutano a ridurre i comportamenti incoerenti all'avvio durante i test di avvio.
La logica FPGA si basa naturalmente su pipeline e strutture parallele. Una delusione comune tra i principianti è aspettarsi un'esecuzione passo-passo simile al software, per poi sentirsi confusi quando tutto accade contemporaneamente. Una lente più utile è decidere cosa ti interessa per un determinato blocco e poi progettare esplicitamente per quel risultato.
Una lente di design a linea singola per prestazioni e mapping:
• Attraversamento (elementi per clock)
• Latency (cicli dall'input all'output)
• Preferenza di mapping delle risorse (LUT vs BRAM vs DSP)
Ad esempio, una moltiplicazione e accumulo può dedurre le slice DSP pulitamente, ma piccole modifiche nello stile di codifica possono spingere lo strumento verso un'aritmetica basata su LUT. Quando l'utilizzo ti sorprende, spesso vale la pena fermarsi e porsi una domanda leggermente scomoda: hai effettivamente descritto la struttura hardware che intendevi, o hai descritto qualcosa di funzionalmente equivalente che costa più risorse?
La simulazione accetterà felicemente costrutti che l'hardware reale non può implementare nel modo in cui potresti immaginare. Mantenere chiaro il tuo confine sintetizzabile riduce la falsa fiducia e rende i risultati della simulazione più portabili sulla scheda.
Modelli comuni da mantenere raggruppati su una sola linea come promemoria veloce:
• Evitare ritardi (#) nella logica sintetizzabile
• Non dipendere dall'inizializzazione a meno che tu non abbia confermato il comportamento di dispositivo/strumento
• Fare attenzione a latch indesiderati da assegnazioni combinatorie incomplete
• Utilizzare sincronizzatori appropriati per il passaggio tra domini di clock
Un'abitudine che tende a ripagare è scrivere piccoli testbench auto-verificanti che convalidano le assunzioni che sei emotivamente tentato di trascurare: comportamento di reset, rollover del contatore, protocolli di handshake e condizioni limite. Quando i progetti crescono, questi test diventano meno un lavoro extra e più la cosa che ti impedisce di mettere in dubbio tutto.
Debugga sistematicamente con simulazione e visibilità on-chip (ILA)
Anche un'eccellente simulazione non promette un comportamento corretto della scheda. L'hardware reale porta jitter di clock, ritardi I/O, stati iniziali sconosciuti e ingressi asincroni che non si allineano gentilmente al tuo bordo di clock. I debugger più veloci di solito non sono quelli che fanno modifiche casuali, ma quelli che ristrutturano il problema con osservazioni strutturate e possono spiegare quale prova ha cambiato la loro opinione.
Un testbench robusto controlla il comportamento su molti cicli e non evita scenari scomodi. Se modelli stimoli realistici, la simulazione diventa un luogo dove costruisci fiducia, non solo un luogo dove osservi un segnale che si alterna e speri che significhi qualcosa.
Stimoli realistici che tendono a rivelare logica fragile:
• Rimbalzo del pulsante
• Errori di incapsulamento UART
• Backpressure in interfacce di streaming
• Sequenze di reset con temporizzazione inadeguata
Aiuta anche separare i bug in due categorie in modo da non inseguire il tipo errato di correzione:
• Bug funzionali: la logica RTL è errata
• Bug di integrazione: la RTL è a posto, ma orari/reset/ vincoli / assunzioni I/O sono errati
La simulazione è eccellente nel rilevare bug funzionali; il collaudo della scheda ha un modo di rivelare bug di integrazione che non volevi credere fossero possibili.
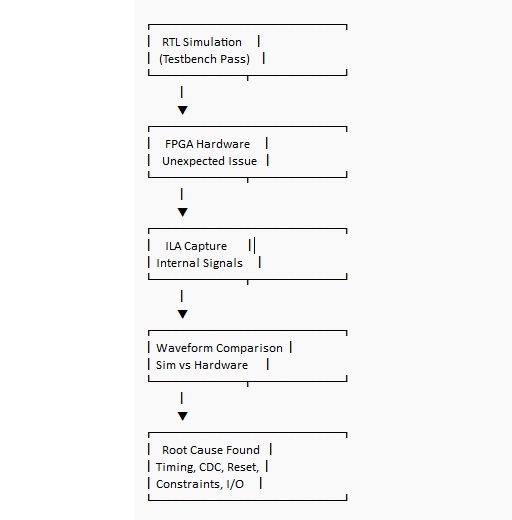
Quando il comportamento dell'hardware non coincide con il tuo testbench, l'Integrated Logic Analyzer (ILA) è spesso il modo più diretto per sostituire la speculazione con una traccia che puoi studiare. Prova segnali che rappresentano decisioni e confini all'interno del design, quindi cattura il momento in cui le cose divergono e confrontalo con l'onda simulata prevista.
Segnali che tendono a essere sonde di alto valore:
• Codifiche di stato FSM
• handshake validi/pronti
• flag FIFO pieni/vuoti
• uscite del sincronizzatore di reset
Un flusso di lavoro pratico è iniziare con meno sonde e una finestra di cattura più ampia. Man mano che impari dove si trova il guasto, puoi stringere il trigger e aggiungere dettagli. Un eccesso di strumentazione può ridurre il margine di temporizzazione e complicare le costruzioni, quindi è spesso più sano trattare l'inserimento dell'ILA come un passo di misurazione focalizzato piuttosto che qualcosa che mantenere giusto per ogni evenienza.
Alcuni dei fallimenti più istruttivi si verificano quando la simulazione sembra impeccabile e la scheda è instabile. Questa discrepanza può sembrare scoraggiante, ma è anche dove l'intuizione dell'FPGA diventa più acuta, perché la soluzione è solitamente nella temporizzazione, nei vincoli o nell'igiene dei segnali piuttosto che nell'algoritmo.
Cause comuni di divergenza tra simulazione e scheda:
• Vincoli di clock mancanti o errati
• Metastabilità da ingressi non sincronizzati
• Variazione della temporizzazione del rilascio del reset attraverso il chip
• Problemi CDC tra più domini di clock
• Differenze nelle condizioni iniziali
Una prospettiva che tende ad accelerare l'apprendimento è trattare la temporizzazione e la osservabilità come proprietà che costruisci deliberatamente nel design. Quando i tuoi piccoli progetti definiscono esplicitamente i clock, vincolano l'I/O, sincronizzano i passaggi e espongono segnali interni per la misurazione, trascorri meno tempo a sperare che funzioni e più tempo a fare miglioramenti controllati e spiegabili. Questa mentalità si estende naturalmente da un LED lampeggiante a pipeline più grandi, interfacce e sistemi embedded sullo stesso dispositivo.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) e Intel (Altera) forniscono entrambi famiglie FPGA che sembrano comparabili sulla carta, ed è facile sentirsi sicuri dopo una rapida scansione del datasheet. L'umore tende a cambiare in seguito, quando le realtà ingegneristiche quotidiane iniziano a decidere il ritmo: il comportamento degli strumenti sul tuo dispositivo e grado di velocità esatti, se l'IP che presumevi di poter utilizzare è effettivamente licenziabile nella tua organizzazione, se un design di riferimento si allinea veramente con i tuoi clock e reset, e se la chiusura temporale rimane stabile una volta che il design diventa di produzione.
Un processo di selezione si mantiene meglio quando tratti l'FPGA come un sistema di consegna, dispositivo + strumenti + IP + schede + documentazione + manutenibilità a lungo termine, perché è lì che i team guadagnano slancio (e sonno) o accumulano ansia silenziosa per il programma.
| Caratteristica |
Xilinx (AMD) |
Intel (Altera) |
| Posizione di Mercato |
Storicamente il leader di mercato, noto per un ampio portafoglio di prodotti e per essere il primo ad entrare nel mercato con nuove tecnologie. |
Forte concorrente, particolarmente potente nelle applicazioni di data center e networking, sfruttando l'abilità di produzione di Intel. |
| Architettura Fondamentale |
La logica è principalmente basata su Look-Up Tables (LUT) a 6 ingressi, offrendo alta granularità e flessibilità. |
Utilizza i Moduli di Logica Adattiva (ALM), che sono più complessi e possono essere configurati come LUT più grandi, migliorando potenzialmente la densità logica per alcuni progetti. |
| Suite Software |
Vivado Design Suite e Vitis Unified Software Platform. Spesso lodata per la sua interfaccia user-friendly per sviluppatori esperti. |
Quartus Prime Design Suite. Alcuni utenti trovano la sua GUI più intuitiva per i principianti, ed è conosciuta per tempi di compilazione più rapidi in alcuni scenari. |
| Famiglie High-End |
Versal ACAPs (Adaptive Compute Acceleration Platforms) che combinano motori scalari, adattabili e intelligenti. |
FPGA Agilex, conosciuti per alte prestazioni e efficienza energetica, con alcuni benchmark che mostrano un vantaggio di prestazione per watt. |
| Focalizzazione sull'Ecosistema |
Forte attenzione all'integrazione del processore e FPGA, come visto nella famiglia Zynq. Popolare per lo sviluppo di applicazioni. |
Ben adatto per progetti System-on-Chip e applicazioni industriali, con un forte portafoglio IP per networking e RF. |
Definire la Selezione Utilizzando Vincoli Verificabili, Non Aspettative del Marchio
Iniziare con requisiti che puoi testare precocemente, non impressioni da progetti precedenti. L'obiettivo è ridurre le "sorprese alla settimana 10," che è dove la frustrazione e il rifacimento tendono ad accumularsi.
Checklist dei vincoli:
• Risorse logiche: LUT/ALM, registri, disponibilità di routing e tetto di utilizzo previsto
• Risorse DSP: conteggio dei blocchi, modalità di precisione, pre-adder, opzioni di cascata/topologia e comportamento di mappatura per i tuoi kernel matematici
• Memoria on-chip: BRAM/URAM (o equivalenti M20K), capacità totale, modalità di porta, larghezza di banda per clock e schemi di contesa
• I/O ad alta velocità: classe SERDES, conteggio dei lane, velocità massima della linea, opzioni di clock di riferimento e supporto del protocollo legato al tuo caso d'uso
• Memoria esterna: varianti DDR3/DDR4/LPDDR, maturità del controller, comportamento di calibrazione e assunzioni di margine SI a livello di scheda
• Latenza e determinismo: obiettivo end-to-end, budget per fase, tolleranza al jitter e strategia CDC (incluso come i reset attraversano i domini)
• Involucro di potenza/termico: stime di commutazione nel caso peggiore, modalità di potenza dei trasmettitori, assunzioni di dissipazione del calore e intervallo ambientale
Progetti FPGA reali mostrano spesso che adattarsi all'interno del dispositivo non garantisce un funzionamento ad alta velocità affidabile. I progetti che appaiono accettabili a una utilizzazione del 70-80% possono diventare instabili dopo aver aggiunto logica di debug, protezione CDC, FIFO, gestione degli errori e margine di temporizzazione necessario per un'operazione pratica.
Se il tuo team ha mai perso una settimana a causa della congestione del routing, l'attrattiva di passare a una dimensione del dispositivo superiore è facile da capire. Il compromesso di costo di solito non è lineare: un componente leggermente più grande può comprare un temporizzatore più tranquillo, meno iterazioni degli strumenti e meno ricostruzioni notturne.
Trattare il Flusso degli Strumenti Come un Requisito Che Non Puoi Ignorare
Il flusso degli strumenti tende a essere il separatore nascosto tra un piano che sembra solido e un piano che continua a slittare. Le persone spesso sottovalutano quanto spazio emotivo venga consumato da iterazioni lente o imprevedibili, specialmente quando una compilazione richiede ore e la modalità di fallimento è vaga.
Checklist di valutazione del flusso degli strumenti:
• Velocità di iterazione: sintesi + posizionamento/routing + tempo di bitstream sull'hardware CI, non su una macchina dimostrativa del fornitore
• Comportamento di chiusura temporale: tendenze di QoR, stabilità tra semi e sensibilità a piccole variazioni di vincolo
• Vincoli e osservabilità: chiarezza SDC/XDC, accuratezza della modellazione del clock, gestione dei percorsi falsi/multicycle e quanto siano debuggabili le violazioni
• Strumentazione di debug: flusso di inserimento dell'analizzatore logico, flessibilità della sonda, profondità di trigger e quante volte devi ricompilare per osservare i segnali
• Adattamento all'ambiente: versioni OS supportate, compilazioni in headless, attriti di licenza e quanto bene si adatta al flusso di lavoro del tuo team
• Amicizia CI/VCS: riproducibilità, output deterministici (per quanto gli strumenti lo consentano), scriptabilità e dolore di aggiornamento
Prima di impegnarti, esegui un trial di chiusura temporale su qualcosa di rappresentativo (non un giocattolo). Includi i tuoi veri clock, almeno un'interfaccia di memoria esterna e almeno un blocco di I/O ad alta velocità. Traccia:
• Tempo di compilazione wall-clock per iterazione
• Stabilità del slack attraverso alcuni semi
• Quanto rapidamente un ingegnere può diagnosticare i primi tre problemi di temporizzazione senza conoscenze tribali
Quell'esperimento tende a produrre una sorta di chiarezza che le checklist delle funzionalità non offrono. Rivela anche se il tuo team si sentirà sicuro o costantemente teso durante la fase di integrazione.
Disponibilità IP e Licenze: Dove i Timelines Comportano Sospensioni
Anche quando le risorse FPGA grezze sembrano simili, i tempi spesso dipendono dalle realtà degli IP. Questo è il punto in cui i team possono sentirsi colti alla sprovvista: il core esiste, ma il modello di licenza, il lavoro di integrazione o la qualità della documentazione lo trasformano in un lento trascinarsi.
Checklist per IP e licenze:
• Stack di protocolli: PCIe, Ethernet MAC/PCS, JESD204, controller DDR e qualsiasi interfaccia di nicchia su cui fai affidamento
• Termini di licenza: bloccati su nodo vs flottanti, componenti aggiuntivi, implicazioni per build-server/CI e qualsiasi vincolo di runtime o distribuzione
• Design di riferimento: conteggi delle corsie, piano di clock, sequenza di reset, architettura DMA e se corrisponde ai confini del tuo sistema
• Orizzonte di supporto: aspettative di manutenzione a lungo termine, frequenza di patch e come vengono gestiti i problemi
Un punto sottile che i team imparano a caro prezzo: l'IP disponibile non è lo stesso dell'IP "drop-in". Le dimostrazioni in laboratorio possono nascondere il lavoro di integrazione necessario per raggiungere i tuoi obiettivi di latenza, buffering e clock. Pianificare tempo per la validazione e favorire IP con documentazione diretta e esempi conosciuti spesso riduce il livello di stress in seguito, anche se la valutazione iniziale sembra più lenta.
Ecosistema della scheda, Rischio di Avvio e il Comfort delle Piattaforme Conosciute
La scelta dell'FPGA è legata alla realtà della scheda. Durante l'avvio, il tempo scompare frequentemente nell'incertezza della piattaforma piuttosto che nel RTL: una restrizione tempo mancata, una dipendenza da reset che non era ovvia o un canale di trasmettitore che è marginale solo a certe temperature.
Checklist per schede e piattaforme
• Schede di valutazione e piattaforme di riferimento: disponibilità, stabilità delle revisioni e se il design è ampiamente utilizzato nel settore
• Linee guida per la fornitura di energia: obiettivi della PDN, approccio al disaccoppiamento, aspettative sulle sequenze di alimentazione e assunzioni sulla tolleranza
• Riferimenti per layout ad alta velocità: indicazioni per il routing del trasmettitore, note di conformità e stackup provati
• Accesso al debug: stabilità JTAG, modalità di avvio/configurazione, supporto flash di configurazione e visibilità su rail/clock
• Responsività del supporto: canali dei fornitori, rapporto segnale-rumore della comunità e tempi di risposta per problemi di strumenti/IP
Utilizzare una piattaforma ampiamente adottata con design di riferimento provati può rendere l'avvio del sistema più strutturato e prevedibile. Questo approccio aiuta la risoluzione dei problemi a passare da una grande incertezza a una verifica misurabile passo dopo passo, migliorando l'efficienza dello sviluppo.
Chiusura Temporale
La chiusura temporale è dove le differenze tra i fornitori diventano tangibili, specialmente quando l'utilizzo aumenta e più domini temporali interagiscono. In questa fase, i progressi nel design possono rimanere stabili e prevedibili o diventare difficili quando piccoli cambiamenti creano grandi variazioni temporali.
• Scalabilità della congestione: come la pressione del routing aumenta man mano che l'utilizzo cresce e dove inizia a picchiare
• Predicibilità Fmax: con quale frequenza i vincoli moderati ti avvicinano, rispetto alla necessità di una regolazione manuale pesante
• Qualità dei report: se i report temporali indicano correzioni attuabili, non solo lunghe liste di violazioni
• Robustezza: comportamento attraverso le variazioni PVT e attraverso i semi di implementazione
È generalmente più sicuro assumere che lo sforzo di chiusura cresca in modo non lineare con la densità. Oltre una certa soglia, una piccola modifica RTL può ribaltare il slack da sano a fragile. Slack architetturale, piping, floorplanning selettivo e scegliere un dispositivo con spazio per respirare, spesso supera la regolazione eroica dei vincoli che nessuno si diverte a mantenere.
Confrontare il Parte Esatta
Le specifiche cambiano tra generazioni e all'interno di una singola famiglia. Due parti con nomi simili possono comportarsi in modo sufficientemente diverso da interrompere un piano, specialmente una volta che l'imballaggio, il grado di velocità e la maturità degli strumenti entrano in gioco.
• Grado di velocità: Fmax raggiungibile, comportamento del margine del trasmettitore e differenze nel modello temporale
• Pacchetto: conteggio I/O, posizionamento delle banche, impatto SI, comportamento termico e vincoli di assemblaggio
• Limiti delle caratteristiche SKU: blocchi disabilitati, capacità del trasmettitore ridotta, rapporti di memoria o limitazioni di protocollo su alcune varianti
• Maturità dello strumento: livello di supporto del dispositivo, frequenza di rilascio e se il tuo team può standardizzarsi su una versione stabile dello strumento
Metodo di confronto pratico:
• Modelli temporali dei fornitori mappati ai tuoi orologi e interfacce reali
• Stima della potenza utilizzando frequenze di toggling realistico, cicli di lavoro e impostazioni del trasmettitore
• Vincoli di pinout/banca allineati ai requisiti della tua scheda e alla mappa dei connettori
• Versioni dello strumento con cui la tua organizzazione può convivere per la vita del prodotto (incluso CI)
Un Quadro Decisionale Che Tende a Resistere Quando Le Cose Diventano Stressanti
Quando la pressione del programma aumenta, un framework ancorato a misurazioni aiuta ad evitare pivot guidati dal rimpianto. Aiuta anche il team a sentirsi più sereno, perché le decisioni hanno una traccia cartacea legata ai risultati osservati piuttosto che all'ottimismo.
Ordine di selezione bilanciato:
1) Blocca i requisiti misurabili: risorse, I/O, memoria, latenza e budget di potenza/termico.
2) Prototipa il sottosistema più difficile su ciascun candidato: comportamento temporale + flusso di debug + ciclo di build/CI.
3) Valuta la maturità dell'IP e la licenza rispetto al tuo piano di integrazione, non ai riassunti di marketing.
4) Scegli l'opzione con margine e il ciclo di iterazione più prevedibile, piuttosto che quella che a malapena supera i minimi.
La conclusione principale è che il miglior FPGA è raramente quello con i numeri più appariscenti. I team di solito si muovono più velocemente e con meno ripensamenti quando la piattaforma supporta una convergenza costante, build ripetibili e soluzioni manutenibili durante il ciclo di vita del prodotto.
La Core Toolchain

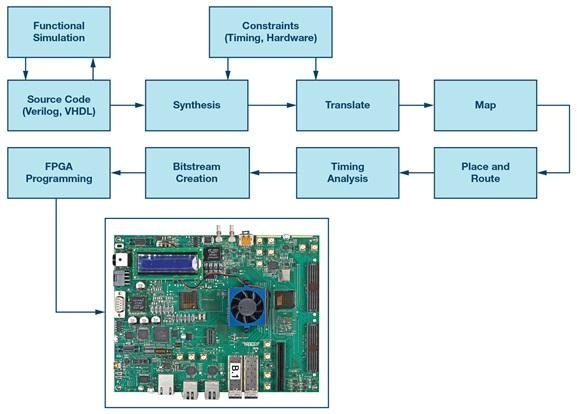
Il ruolo di Vivado nel flusso di lavoro FPGA
Vivado tende a diventare il hub operativo di un progetto FPGA Xilinx, non perché sia glamour, ma perché è dove ogni ipotesi viene alla fine testata contro la realtà degli strumenti. Assorbe HDL e vincoli, produce una netlist, esegue il posizionamento e il routing bilanciando le regole temporali e di design fisico, e poi genera un bitstream che programma il dispositivo.
Un modo pratico per comprendere Vivado è vederlo come due sistemi connessi: un sistema di conversione RTL a netlist e un ottimizzatore di implementazione fisica. Questo spiega perché un RTL logicamente corretto può comunque produrre risultati instabili o incoerenti quando i vincoli sono incompleti, le definizioni degli orologi sono inaccurate, o la struttura del design crea difficoltà di routing e temporizzazione.
La maggior parte dei progetti segue un pipeline familiare, anche quando i dettagli differiscono per famiglia di dispositivi e stile di flusso.
• Sintesi: traduce RTL in una rappresentazione a livello di gate e inferisce strutture specifiche del dispositivo.
• Implementazione: esegue posizionamento, routing e ottimizzazione guidata dai tempi sotto vincoli fisici.
• Generazione di bitstream: emette l'immagine di configurazione e verifica il risultato implementato contro i vincoli e le regole dello strumento.
Un programma tende a diventare teso non quando un bitstream è prodotto una sola volta, ma quando il team ha bisogno che il bitstream si comporti come un'uscita affidabile: risultati simili attraverso le ricostruzioni, margini di temporizzazione che sopravvivono alla velocità target e stabilità quando vengono effettuate piccole modifiche RTL per correzioni funzionali. È lì che ciò che è stato costruito ieri smette di essere confortante.
I team che si muovono più velocemente nel tempo di solito smettono di trattare i report come documentazione e iniziano a trattarli come prove ingegneristiche. Quando gli artefatti di build vengono raccolti in modo coerente, le discussioni di design diventano meno emotive e più concrete, il che è un sollievo quando le scadenze si avvicinano.
• Rapporti di sintesi/implementazione: utilizzo, primitive inferite, avvisi e sommari strutturali.
• Uscite temporali: WNS/TNS, endpoint in fail, percorsi dettagliati e sommari di interazione degli orologi.
• Vincoli XDC: orologi, regole I/O, eccezioni e assegnazioni di pin fisici.
• Punti di controllo implementati (DCP): snapshot riproducibili che supportano iterazioni rapide e esperimenti controllati.
Un modello che si manifesta nel lavoro reale è che un insieme di report ordinati e internamente coerenti spesso prevede progressi più fluidi rispetto a un singolo banner verde "PASS". Il banner può nascondere fragilità; i report di solito non lo fanno.
Installazione e configurazione dell'ambiente
Una configurazione che semplicemente avvia la GUI è facile da celebrare e facile da rimpiangere in seguito. Le configurazioni di cui i team si fidano sono noiose in modo positivo: si comportano allo stesso modo sotto automazione, sono coerenti tra le macchine e non ti sorprendono dopo un aggiornamento dello strumento.
Scegli l'edizione Vivado ML che corrisponde ai tuoi obiettivi di dispositivo, quindi abilita solo le famiglie di dispositivi che intendi realmente costruire. Questo riduce l'uso del disco e il tempo di indicizzazione, e riduce anche le probabilità di errori di configurazione accidentali tra famiglie che possono far perdere un pomeriggio.
Nei team di sviluppo multi-scheda, mantenere un elenco definito di dispositivi supportati per ogni progetto aiuta a mantenere lo sviluppo più controllato e coerente rispetto a fare affidamento su qualsiasi strumento o parte possa essere installato.
Le uscite di Vivado possono variare tra le versioni perché gli algoritmi di posizionamento, routing e temporizzazione si evolvono e i bug vengono corretti (o sostituiti con bug diversi). Molti team ottengono build più calme bloccando una versione dello strumento per ramo di rilascio e aggiornando in passi pianificati piuttosto che lasciando che fluttui continuamente.
Quando si prova una versione più recente, i team spesso confrontano i segnali pratici della salute degli strumenti prima di adottarla come una nuova base: margini di temporizzazione, cambiamenti di utilizzo, delta di avviso e qualsiasi nuovo messaggio di copertura dei vincoli. Il tempo speso per quel confronto è di solito più facile che discutere tardi nel ciclo se la temporizzazione è improvvisamente peggiorata senza motivo.
Per le compilazioni da riga di comando, i sistemi CI e i server di build condivisi, l'ambiente di sviluppo deve comportarsi in modo coerente su tutti i sistemi invece di dipendere dalle configurazioni delle singole macchine.
• Script di impostazioni: importa le giuste impostazioni degli strumenti in modo che percorsi, librerie e dipendenze di runtime si risolvano in modo coerente.
• Flussi driven da Tcl: preferisci le build scriptate per esecuzioni ripetibili, report uniformi e integrazione CI.
• Disciplina dell'interfaccia di build: mantieni stabili input e output affinché le modifiche siano intenzionali e revisionabili.
Un flusso di lavoro comune nello sviluppo è prima completare una build GUI stabile per verificare il design, quindi passare a un flusso basato su Tcl in modo che il processo di build non dipenda più dalle impostazioni GUI, dai dati memorizzati nella cache o dalle differenze tra le macchine di sviluppo.
I Report che vorrai leggere come Diagnostica
La maggior parte dei momenti di fallimento del design non sono misteriosi a lungo se i report vengono letti come una storia di ciò in cui lo strumento credeva. Gli avvisi, la copertura dei vincoli e i percorsi di temporizzazione tendono a documentare il modo di fallimento in bella vista, anche se non sempre nell'ordine più amichevole.
I team migliorano più rapidamente quando trattano le uscite di Vivado come un ciclo di feedback quotidiano piuttosto che come qualcosa da aprire solo quando la build si interrompe.
Questi report sono spesso il primo posto dove il drift dell'intento diventa visibile, e questo può essere stranamente rassicurante: almeno il problema è concreto.
• Utilizzo delle risorse: LUT, FF, BRAM, DSP, URAM rispetto ai limiti e al margine del dispositivo.
• Controlli di inferenza: stili di RAM inaspettati, inferenza DSP mancante, mapping delle primitive sorprendente.
• Bandiera rossa strutturale: reti ad alta fan-out, muxing ampio, lunghe catene combinatorie.
• Avvisi: inferenza di latch, gestione incompleta della sensibilità, logica non connessa o ridotta.
L'inferenza di latch e i percorsi combinatori lunghi e non intenzionali si presentano frequentemente nella pratica. Lo strumento li implementerà senza lamentarsi, e questo può sembrare ingannevole quando la temporizzazione in seguito si rifiuta di cooperare in modi che sembrano casuali fino a quando non vengono letti i report sui percorsi.
La chiusura della temporizzazione diventa meno stressante quando il team sa cosa sta ottimizzando lo strumento e perché sta scegliendo determinati compromessi.
• Segnali di slack: WNS come la peggior violazione singola; TNS come la diffusione complessiva delle violazioni.
• Suddivisione dei percorsi: dove si accumula il ritardo (profondità logica, routing, clocking o assunzioni sui vincoli).
• Modellazione degli orologi: se i percorsi sono analizzati come previsto, ignorati o raggruppati in modo errato.
Una lezione sfumata che i team esperti interiorizzano è che il dolore della temporizzazione è spesso prima un problema di modellazione dei vincoli e in secondo luogo un problema RTL. Quando il modello di clock è errato, può trascorrere giorni ottimizzando i punti finali sbagliati e sembrare comunque che lo strumento non stia ascoltando.
I gap nei vincoli sono un colpevole recidivo, in parte perché non sembrano sempre drammatici fino a quando il progetto non è ormai avanzato.
• Gap nella definizione di clock: clock primari mancanti o errati.
• Gap nei clock generati: clock divisi/moltiplicati/indirizzati non dichiarati, costringendo lo strumento a indovinare.
• Gap nella definizione di I/O: vincoli di I/O mancanti che portano a assunzioni ottimistiche e successivi problemi a livello di scheda.
• Uso improprio delle eccezioni: eccezioni mancanti o eccezioni troppo ampie per essere affidabili.
Un'abitudine pragmatica è trattare l'XDC come una specifica vivente piuttosto che come un file patch. Quando vengono introdotte eccezioni, i team che dormono meglio tendono a mantenerle ristrette, spiegate e legate a una reale relazione di temporizzazione piuttosto che usarle per silenziare violazioni che meritano attenzione.
Strategia dei vincoli XDC
Il file XDC è dove l'intento di design è costretto a diventare esplicito. Quando è leggermente sbagliato, il comportamento temporale risultante può apparire caotico anche se lo strumento è perfettamente deterministico.
Definisci gli orologi in modo esplicito, quindi verifica che lo strumento li abbia propagati come ti aspettavi. I problemi di modello di clock sono spesso più facili da correggere rispetto a problemi di temporizzazione architettonica più profondi, rendendoli più semplici da risolvere durante l'analisi della temporizzazione e il debugging.
• Orologi primari: definiti da pin o uscite di MMCM/PLL.
• Orologi generati: definiti per domini divisi, moltiplicati o inoltrati.
• Relazioni asincrone: dichiarate tramite gruppi di clock o relazioni esplicite.
Su schede reali, un orologio generato mancante può produrre un'immagine temporale fuorviante che brucia giorni, specialmente quando lo strumento ottimizza verso punti finali che non erano mai stati destinati ad essere analizzati insieme.
I/O vincoli plasmano le assunzioni elettriche e temporali che lo strumento utilizza, e questo può silenziosamente determinare se il successo in laboratorio si traduce in "successo del sistema".
• Standard elettrici: standard e tensioni I/O allineati con il design della scheda.
• Disciplina di pinning: bloccare le posizioni dei pin una volta che la mappatura si stabilizza per evitare flussi.
• Tempistiche dell'interfaccia: ritardi di input/output che riflettono il dispositivo esterno, non i valori predefiniti dello strumento.
Una delusione comune nelle fasi finali è: ha rispettato i tempi nella costruzione, ma l'interfaccia fallisce sotto il traffico reale. Quel risultato spesso risale a assunzioni I/O predefinite che non sono mai state aggiornate per allinearsi al budget temporale della scheda e del dispositivo esterno.
Le eccezioni possono chiarire l'intento e possono anche creare una fragile illusione di progresso se sopravvivono alla loro giustificazione originale.
• Percorsi falsi: usati solo quando il percorso non fa veramente parte del temporizzare funzionale.
• Percorsi multitiro: usati solo quando la relazione di cattura copre veramente più cicli ed è documentata.
• Igiene delle eccezioni: mantenere il set piccolo, rivederlo dopo importanti cambiamenti RTL/pipeline e ritirare voci superate.
Alcuni dei bug di temporizzazione più costosi provengono da eccezioni che erano accurate un tempo e poi sono diventate silenziosamente inaccurate dopo un cambiamento della pipeline. Lo strumento si conformerà senza lamentarsi, il che è esattamente ciò che rende questo modo di fallimento così sgradevole.
Modelli di fallimento tipici e come risolverli in modo efficiente
Alcuni problemi si ripetono nei progetti, indipendentemente dal fatto che l'applicazione sia networking, visione, controllo o accelerazione. Riconoscere il modello in anticipo tende a ridurre il carico emotivo del debug, perché il team può passare dal perché sta succedendo a quale manuale si applica.
Questa situazione spesso sembra che lo strumento sia testardo, ma le cause radice sono di solito tracciabili.
• Profondità combinatoria: percorsi lunghi causati da pipelining mancante o insufficiente.
• Pressione di fanout: reti di controllo ad alto fanout che beneficiano di replicazione, buffering o ristrutturazione.
• Modellazione dei vincoli: definizioni o relazioni di clock che caratterizzano male ciò che dovrebbe essere analizzato.
Una sequenza che tende a funzionare bene è: convalidare il modello temporale (clock e relazioni), concentrarsi prima sui punti finali che falliscono peggio, quindi allargarsi ai cambiamenti architetturali solo se le evidenze del percorso lo supportano.
Questa è una delle esperienze più demoralizzanti nel lavoro con FPGA, principalmente perché sembra che la realtà sia ingiusta. Di solito, è solo che la simulazione non ha stressato gli stessi modi di fallimento.
• Comportamento CDC/reset: sequenziamento di reset e attraversamenti di dominio di clock che la simulazione raramente esercita in modo realistico.
• Assunzioni I/O: I/O non vincolati o mal vincolati che producono interfacce reali marginali.
• Comportamento di inizializzazione: dipendenza da valori iniziali che non si mappano pulitamente al comportamento di accensione del dispositivo.
I team che diventano più stabili portano la strategia CDC e di reset nella discussione di design in modo precoce, trattandole come parte dell'architettura di progetto piuttosto che come una fase di pulizia dopo che la "logica reale" è completata.
Questo problema è comune perché il place-and-route risponde in modo brusco ai cambiamenti nella struttura del netlist, anche quando il cambiamento funzionale sembra minore.
• Sensibilità del netlist: piccole ristrutturazioni possono alterare imballaggi, decisioni di posizionamento e congestione di routing.
• Deriva dei vincoli: piccole modifiche XDC (o copertura mancante) possono amplificare la variazione temporale.
• Abitudini di mitigazione: implementazione incrementale, conservazione selettiva della gerarchia e vincoli stabili.
Quando i team adottano queste abitudini di mitigazione, l'iterazione tende a sembrare più prevedibile, il che riduce la tentazione di congelare prematuramente il design per paura di compromettere nuovamente i tempi.
Considerazioni sulle licenze
La concessione di licenze tende a diventare una conversazione quando un progetto incontra limiti di copertura dei dispositivi o quando caratteristiche avanzate sono necessarie per un particolare flusso di lavoro.
• Standard: spesso si allinea con schede di apprendimento entry e mid-range e flussi di base.
• Enterprise: spesso si allinea con un supporto di dispositivi più ampio e capacità avanzate.
Per i team, le licenze fluttuanti supportate da un server di licenze sono spesso più facili da scalare rispetto alle licenze bloccate su nodo, specialmente quando le build vengono eseguite su macchine condivise, server di build dedicati o runner CI. Molti team preferiscono allineare le licenze con la roadmap del dispositivo prima piuttosto che dopo, perché le sorprese relative alle licenze hanno l'abitudine di presentarsi quando passare a dispositivi diversi è già costoso e politicamente difficile.
Un ciclo ingegneristico coerente tende a prevedere progressi più costanti rispetto a qualsiasi singola ottimizzazione intelligente: mantenere i vincoli allineati con la realtà, leggere i rapporti regolarmente (anche quando non si ha voglia), risolvere le cause principali invece di silenziare i sintomi e mantenere le build riproducibili. Quando quel ciclo è stabilito, Vivado sembra meno una scatola nera e più un pannello di strumenti, e la chiusura temporale passa da uno stress dell'ultimo minuto a qualcosa che il team può gestire deliberatamente.
Portfolio e Ecosistema di Xilinx

Scegliere tra i dispositivi Xilinx tende ad andare più fluido quando il punto di partenza è l'integrazione circostante (processori, interfacce di memoria, percorso di avvio e dipendenze a livello di scheda), non solo un confronto dei totali LUT grezzi. Quella cornice di solito corrisponde a come si presentano i reali programmi e i reali rischi.
Un FPGA discreto tende a essere adatto quando il team desidera avere il pieno controllo dell'architettura della scheda e il carico di lavoro tende verso un comportamento hardware deterministico con una superficie software minima. Un SoC di classe Zynq tende a essere adatto quando il design beneficia di una CPU che si trova vicino alla logica di accelerazione in modo che il controllo e il data path possano evolversi insieme senza trasformare la scheda in una negoziazione multi-chip. Un modulo in stile Kria SOM tende a essere adatto quando il piano è di muoversi rapidamente e limitare l'incertezza nell'avvio della scheda trattando il calcolo, la memoria e lo storage di avvio come un blocco costruttivo prequalificato.
L'FPGA discreto tende ad essere adatto per:
• massimo controllo del design della scheda
• pipeline deterministiche con dipendenze software limitate
Lo Zynq SoC tende ad essere adatto per:
• accoppiamento stretto tra CPU e acceleratore
• calcolo/unificazione del controllo su un dispositivo
• evoluzione iterativa HW/SW
Il Kria SOM tende ad essere adatto per:
• tempi di prodotto più brevi
• esposizione ridotta a livello di scheda grazie all'uso di un sottosistema di calcolo convalidato
Gli FPGA semplici spesso si adattano bene quando il problema è causato dalla pressione della chiusura temporale, esigenze I/O insolite o pipeline di streaming che si comportano meglio come hardware a funzione fissa. La latenza prevedibile e i data path strutturati spesso migliorano il controllo, la verifica e il debug, soprattutto quando l'architettura rimane ben organizzata.
I dispositivi standalone si presentano frequentemente in:
• interfacciamento dei sensori
• controllo dei motori
• elaborazione di pacchetti a velocità moderata
• bridging dei protocolli
In campo, una fonte ricorrente di frustrazione non è l'RTL stesso ma gli obblighi della scheda circostante che arrivano silenziosamente e poi dominano il percorso critico. I rail di potenza, la strategia di configurazione e avvio, la generazione di clock, la disposizione della memoria esterna (quando presente) e l'accesso di debug possono trasformarsi nei vincoli che modellano l'intero prodotto. Una regola pratica è che più semplice è la storia della memoria esterna e minori sono i trasmettitori ad alta velocità coinvolti, più soddisfacente diventa l'esperienza FPGA standalone. Non appena i flussi DDR esterni e di avvio a più passaggi diventano inevitabili, l'attrattiva dell'integrazione di un SoC o di un modulo inizia a sembrare meno una caratteristica e più un sollievo.
Le famiglie ottimizzate per costo generalmente puntano a una miscela misurata di LUT, BRAM e DSP sotto budget di potenza controllati. Si presentano spesso in prodotti dove il team di ingegneria desidera una capacità rispettabile senza pagare il costo della scheda e termico che deriva da interfacce estreme.
Le aree di atterraggio comuni includono:
• controllo embedded
• aggregazione I/O di medio livello
• elaborazione del segnale a velocità moderata
Il vantaggio non è solo il prezzo unitario, i team apprezzano spesso che questi componenti rendono più facile rimanere nei limiti termici senza ricorrere a dissipatori di calore aggressivi e possono evitare che il PCB diventi un progetto di layout ad alta velocità. Allo stesso tempo, le build di campo insegnano regolarmente una lezione leggermente scomoda: un dispositivo a costo inferiore può innescare una spesa totale più alta se costringe a compromessi di design nella fase avanzata. Quando il margine temporale è ridotto, piccoli aggiustamenti, un cambiamento nello standard I/O, una modifica nel routing dei clock, uno spostamento del piano di piano, possono ripercuotersi in un carico di verifica e ansia per il programma. Per questi dispositivi, i team di solito risparmiano tempo stabilendo prima la pianificazione del dominio del clock, la strategia CDC e il comportamento di reset, piuttosto che sperare che le micro-ottimizzazioni tardive possano salvare il piano.
Zynq SoC
I dispositivi Zynq combinano l'elaborazione ARM con la logica programmabile, il che consente al design di dividersi in software del piano di controllo e accelerazione del piano dati in un modo che sembra naturale per molti team di prodotto. Questo fa più che migliorare la comodità, rimodella il flusso di lavoro. I team possono iniziare con un riferimento basato su software per la fiducia funzionale, quindi migrare i percorsi caldi nell'hardware man mano che i requisiti di throughput e latenza diventano meno negoziabili.
In distribuzioni che invecchiano bene, la CPU raramente "sostituisce" l'hardware, tende a stabilizzare il prodotto. Il processore finisce per gestire configurazione, telemetria, aggiornamenti, politica di sicurezza e connettività edge, mentre il tessuto gestisce pipeline deterministiche. Questa separazione può essere emotivamente rassicurante per i manutentori: il software assorbe i cambiamenti, l'hardware rimane stabile e le versioni sembrano meno un azzardo.
La CPU comunemente gestisce:
• configurazione
• telemetria
• aggiornamenti
• politica di sicurezza
• connettività edge
Il tessuto comunemente gestisce:
• pipeline di streaming deterministiche
• acceleratori stabili
• datapath sensibili alla latenza
Con l'aumento della densità di calcolo e interfacce sempre più esigenti, i componenti in stile Zynq UltraScale+ riducono la complessità della scheda e del sistema avvicinando i core della CPU, i controllori DDR e le interconnessioni ad alta larghezza di banda al tessuto. Questo diventa attraente in progetti che necessitano sia di determinismo in tempo reale che di un ambiente software capace, specialmente quando il carico di lavoro è un mix piuttosto che un singolo kernel pulito.
I casi d'uso frequenti includono:
• analisi edge
• fusione multi-sensore
• pipeline miste in tempo reale più AI
Un dettaglio che i team esperti imparano a rispettare è che "più tessuto" non si traduce automaticamente in "più prestazioni fornite". I progetti spesso si scontrano con i limiti di banda di memoria prima di esaurire DSP o LUT. I progetti che decidono sulla topologia DMA, la strategia di buffering e le aspettative di coerenza della cache precocemente tendono a raggiungere prestazioni stabili con meno confusione rispetto ai progetti che rimandano le decisioni sul movimento dei dati fino a un'integrazione tardiva.
La partizione raramente riguarda se qualcosa potrebbe essere accelerato, ma è più una questione di se l'accelerazione porta vantaggio dato l'impegno di verifica, la complessità del driver e del runtime, e quante volte la logica è destinata a cambiare. I team spesso avvertono una sorta di tiro alla fune: spingere troppo verso l'hardware può rallentare l'iterazione, mentre lasciarne troppo sulla CPU può portare a obiettivi di throughput che sono perpetuamente quasi raggiunti.
I carichi di lavoro che rimangono spesso sulla CPU più a lungo del previsto includono:
• logica in rapida evoluzione
• comportamento complesso di parsing
• funzionalità con cicli di iterazione rapidi
I carichi di lavoro che spesso premiano l'accelerazione anticipata del tessuto includono:
• algoritmi stabili
• kernel densi di calcolo
• datapath favorevoli allo streaming
Un modello pragmatico è iniziare con un piccolo pezzo end-to-end, spesso un semplice loopback DMA più un acceleratore minimale, prima di costruire l'intero insieme di funzionalità. Quel prototipo limitato tende a far emergere i problemi di integrazione che altrimenti arriverebbero tardi e costosi: comportamento delle interruzioni, allineamento dei buffer, costi di mantenimento della cache e limiti di throughput che compaiono solo sotto carico sostenuto.
Kria SOM e piattaforme di tipo modulo
I Kria SOM raggruppano calcolo, memoria e storage di avvio in un sottosistema pronto, spostando l'impegno lontano dall'avvio della scheda e verso l'ingegneria dell'applicazione. I team spesso apprezzano questo approccio perché contiene incertezze: l'integrità del segnale, il routing DDR, il sequenziamento dell'alimentazione e l'affidabilità dell'avvio sono già stati validati, il che può far sentire le dimostrazioni iniziali meno fragili e la pianificazione meno speculativa.
L'approccio tende a funzionare particolarmente bene quando la differenziazione risiede negli algoritmi, nella topologia I/O e nell'affidabilità della distribuzione piuttosto che in una scheda di calcolo personalizzata. Può anche ridurre il attrito tra team: il lavoro hardware, firmware e applicazione può progredire in parallelo con meno momenti "bloccati dall'avvio".
L'integrazione dei SOM validata copre comunemente:
• integrità del segnale
• routing DDR
• sequenziamento dell'alimentazione
• affidabilità dell'avvio
I team possono rifocalizzare l'impegno su:
• differenziazione della scheda portante
• integrazione del firmware
• comportamento dell'applicazione
• rinforzo della distribuzione
Un SOM spesso ha un costo per unità più alto rispetto a una scheda completamente personalizzata, eppure il costo totale del programma può comunque diminuire quando i tempi sono serrati o il rischio di rendimento della produzione è scomodo. Il guadagno meno ovvio è la prevedibilità del ciclo di vita: con un modulo, il calcolo può talvolta essere trattato come un elemento intercambiabile tra varianti di prodotto, riducendo il churn di redesign quando i requisiti cambiano a metà corso.
Il passo più calmante è convalidare presto che il margine termico del SOM, l'esposizione I/O e la larghezza di banda della memoria corrispondano effettivamente al carico di lavoro previsto, piuttosto che fidarsi della lettura di una scheda delle specifiche. Se l'applicazione si trova a essere limitata dalla larghezza di banda, la regolazione in fase tardiva tende a sembrare come forzare su una porta bloccata, il disallineamento tra la domanda di accelerazione e il sottosistema della memoria del modulo domina semplicemente.
I controlli di idoneità anticipata includono tipicamente:
• involucro termico
• I/O esposti
• larghezza di banda della memoria sostenuta rispetto alla domanda di carico di lavoro
Implementazione dell'AI nell'ecosistema
Vitis AI aiuta a convertire modelli addestrati in progetti di inferenza basati su FPGA utilizzando formati a bassa precisione, spesso INT8, e compilandoli per architetture in stile DPU. Questo conferma rapidamente se un modello può operare sulla piattaforma FPGA. Tuttavia, le prestazioni reali dipendono spesso fortemente dal design del sistema circostante, in particolare dal movimento dei dati e dalla gestione della memoria.
La larghezza di banda end-to-end è generalmente governata da quanto costantemente il sistema può alimentare il DPU. La strategia di batching, il layout dei tensori, la pianificazione DMA, il doppio buffering e la posizione della memoria spesso decidono i FPS consegnati più della capacità computazionale apparente. I team che trattano il DPU come un consumatore di streaming costante, con buffer attentamente organizzati, tendono ad evitare la delusione comune di TOPS teorici impressionanti ma risultati a livello di sistema deludenti.
Le manopole per modellare le prestazioni comunemente includono:
• strategia di batching
• layout dei tensori
• pianificazione DMA
• doppio buffering
• posizione della memoria
Nelle implementazioni, piccole scelte di implementazione si accumulano in modi che possono essere difficili da prevedere dai microbenchmark di laboratorio. Buffer non allineati possono ridurre silenziosamente la banda utile. Una manutenzione cache eccessiva può assorbire tempo della CPU e creare jitter. Pipeline ad alta copia possono annullare gran parte del beneficio ottenuto dalla quantizzazione. Un approccio basato è misurare la larghezza di banda e la latenza a ogni limite e poi concentrare gli sforzi sul confine attualmente più critico.
I limiti di misura utili includono:
• sensore a DDR
• DDR ad acceleratore
• acceleratore a post-elaborazione
Un modello mentale utile è considerare la pipeline AI come una rete di flusso vincolata. Con questa cornice, la selezione del dispositivo diventa meno una questione di perseguire il numero di calcolo più grande e più una questione di scegliere l'opzione che rilassa il collo di bottiglia dominante e mantiene il comportamento della pipeline prevedibile.
Ecosistema e abilità
L'ecosistema Xilinx si estende oltre il silicio all'abilitazione circostante che mantiene i team in movimento: toolchain, IP, design di riferimento, schede dei partner e risorse di formazione. Negli ambienti accademici, il Programma Universitario è spesso apprezzato perché riduce il dolore di configurazione ricorrente, l'accesso agli strumenti, la disponibilità delle schede e la struttura del laboratorio, quindi i progressi iniziali hanno meno probabilità di bloccarsi per problemi ambientali piuttosto che per imparare l'ingegneria effettiva.
I componenti dell'ecosistema includono:
• toolchain (Vivado, Vitis)
• cataloghi IP
• design di riferimento
• schede dei partner
• programmi di formazione
• risorse del Programma Universitario
Una volta ridotta la frizione di onboarding, gli apprendisti possono spendere la loro energia sulle abitudini che si traducono direttamente in lavoro professionale: routine di chiusura temporale, disciplina di piping, strategia di verifica e giudizio di co-progettazione hardware/software. Queste competenze tendono a mostrare il loro valore durante l'integrazione, quando i risultati sono modellati più dalla velocità di iterazione e dalla coesione del sistema che da un benchmark kernel isolato.
Le competenze trasferibili includono:
• abitudini di chiusura temporale
• disciplina di piping
• strategia di verifica
• co-progettazione hardware/software
Un principio di selezione che rimane coerente in tutta la gamma
Un approccio di selezione affidabile inizia dai vincoli del sistema piuttosto che dai livelli di marketing. I team generalmente ottengono decisioni più chiare quando scrivono gli obiettivi operativi e le realtà progettuali in anticipo, poi scelgono il livello di integrazione, FPGA, Zynq SoC, o SOM, che riduce le maggiori fonti di incertezza per il loro programma specifico. Questo tende a produrre scelte che si sentono meglio mesi dopo, quando il ritmo di integrazione e iterazione conta più di un confronto di parti sulla carta.
I vincoli da definire presto includono:
• obiettivi di latenza
• esigenze di larghezza di banda sostenuta
• requisiti di interfaccia
• limiti termici
• cadenza di aggiornamento
• budget di verifica
In molti programmi, l'opzione che mantiene il movimento dei dati semplice e il ciclo di sviluppo stretto finisce per essere quella che invecchia meglio, anche se il suo prezzo per unità non è il più attraente a prima vista.
Conclusione
Apprendere il design FPGA di Xilinx diventa più facile quando ogni progetto segue un processo stabile e ripetibile. Risultati solidi dipendono da HDL pulito, vincoli corretti, controlli temporali accurati, simulazione e validazione su hardware reale. Iniziando con design semplici e costruendo buone abitudini di debug, i principianti possono sviluppare competenze FPGA affidabili per sistemi digitali più complessi.
Domande Frequenti [FAQ]
1. Perché i principianti FPGA spesso lottano anche quando il loro codice HDL appare logicamente corretto in simulazione?
Molti problemi iniziali degli FPGA non sono causati dall'RTL stesso, ma dal divario tra le assunzioni di simulazione e il comportamento fisico dell'hardware. La simulazione di solito nasconde problemi relativi ai vincoli di clock, al tempo di reset, agli standard I/O, alla metastabilità e alla chiusura temporale. Un design può simulare perfettamente pur fallendo sull'hardware perché gli strumenti FPGA interpretano i clock in modo diverso, i vincoli sono incompleti o gli input asincroni sono gestiti in modo errato.
2. Perché i vincoli di temporizzazione sono considerati una parte fondamentale del design FPGA anziché un passaggio finale di ottimizzazione?
I vincoli di temporizzazione definiscono come gli strumenti FPGA interpretano i clock, le relazioni temporali degli I/O, i clock generati e i domini asincroni. Senza vincoli accurati, Vivado può ottimizzare il design utilizzando assunzioni errate, portando a rapporti temporali fuorvianti e a un comportamento hardware instabile. Molti fallimenti FPGA si verificano anche quando la logica stessa è corretta perché i clock non sono stati dichiarati correttamente, il timing degli I/O è stato ignorato o le eccezioni sono state applicate in modo troppo ampio. Nella pratica, i vincoli agiscono come una descrizione formale dell'intento di design, consentendo agli strumenti di costruire hardware che corrisponde al reale comportamento elettrico.
3. Perché il debug degli FPGA spesso richiede sia simulazione che strumenti on-chip come l'ILA?
La simulazione è altamente efficace per rilevare bug funzionali, ma non può riprodurre completamente gli effetti del mondo reale sull'hardware, come jitter, input asincroni, ritardi a livello di scheda, metastabilità e variazioni all'accensione. Gli strumenti di debug on-chip come l'Integrated Logic Analyzer (ILA) forniscono visibilità nei segnali interni degli FPGA mentre il sistema opera in condizioni reali. Questo consente di catturare le transizioni di stato reali, il comportamento FIFO, i handshake e le relazioni temporali direttamente all'interno del dispositivo. Combinare la simulazione con il debug ILA crea una comprensione più completa di perché l'hardware si discosti dal comportamento atteso.
4. Perché gli ingegneri FPGA esperti preferiscono flussi di lavoro disciplinati e ripetibili piuttosto che configurazioni di progetto in continua evoluzione?
I flussi di lavoro ripetibili riducono l'incertezza e rendono più facile isolare i fallimenti. Utilizzare la stessa scheda di sviluppo, la stessa struttura di clock, la stessa strategia di reset e lo stesso modello di progetto consente agli ingegneri di concentrarsi sulla logica in fase di sviluppo piuttosto che ripetutamente fare debug dell'ambiente stesso. I progetti FPGA coinvolgono molte variabili interagenti, inclusi vincoli, clock, comportamento di sintesi e configurazione a livello di scheda. Quando troppe variabili cambiano simultaneamente, il debug diventa imprevedibile e emotivamente estenuante. Flussi di lavoro stabili migliorano la fiducia poiché le modifiche possono essere ricondotte a decisioni di design specifiche piuttosto che a differenze ambientali sconosciute.
5. Perché la progettazione hardware FPGA è fondamentalmente diversa dalla programmazione software tradizionale?
Il software esegue istruzioni in modo sequenziale, mentre l'hardware FPGA opera attraverso strutture logiche concorrenti che funzionano simultaneamente. L'HDL descrive il comportamento fisico dell'hardware piuttosto che il flusso di esecuzione procedurale. I principianti spesso si aspettano un comportamento simile a quello del software, poi rimangono confusi quando più blocchi hardware reagiscono contemporaneamente allo stesso bordo di clock in parallelo. La progettazione FPGA quindi enfatizza pipeline, relazioni temporali, sincronizzazione, mappatura delle risorse e comportamento del dominio di clock invece di considerare solo l'ordine delle istruzioni. Comprendere la concorrenza è uno dei cambiamenti mentali più importanti nell'ingegneria FPGA.
6. Perché piccole modifiche all'RTL possono improvvisamente causare gravi problemi di chiusura temporale nei progetti FPGA?
Il comportamento temporale degli FPGA dipende fortemente dal posizionamento, dalla congestione del routing, dal fanout, dalle relazioni di clock e dall'uso delle risorse fisiche. Anche piccole modifiche all'RTL possono alterare il modo in cui gli strumenti di sintesi e routing mappano la logica attraverso il dispositivo. Una modifica apparentemente innocua può aumentare la pressione del routing, allungare i percorsi combinatori o influenzare le decisioni di posizionamento in modi che riducono significativamente il margine temporale. Questa sensibilità diventa più severa man mano che l'utilizzo aumenta, specialmente quando i design si avvicinano ai limiti di routing o clocking.
7. Perché i progetti FPGA frequentemente diventano vincolati dalle realtà a livello di scheda piuttosto che solo dalla complessità dell'RTL?
Man mano che i sistemi FPGA crescono, le sfide relative alla sequenza di alimentazione, alla disposizione DDR, alla generazione di clock, al comportamento termico, all'integrità del segnale e al routing dei trasmettitori spesso dominano il tempo di sviluppo. L'RTL può funzionare correttamente, mentre l'infrastruttura hardware circostante introduce instabilità o fallimenti di integrazione. Gli ingegneri scoprono frequentemente che le decisioni di design della scheda, la sequenza di reset e il comportamento dell'interfaccia di memoria influenzano il successo complessivo del progetto più dell'HDL stesso. Questo è particolarmente vero nei sistemi ad alta velocità che utilizzano memoria DDR esterna e interfacce SERDES.
8. Perché molti team FPGA valutano i toolchain con la stessa serietà dell'hardware FPGA stesso?
La toolchain FPGA influenza direttamente il tempo di compilazione, la stabilità della chiusura temporale, l'efficienza del debug, l'integrazione CI e la produttività ingegneristica complessiva. Risultati di implementazione lenti o inconsistenti possono aumentare drasticamente il tempo di iterazione e la pressione del programma. I team valutano spesso la qualità della sintesi, la chiarezza del rapporto temporale, l' strumentazione di debug e la riproducibilità prima di impegnarsi su una piattaforma. Negli ambienti di sviluppo reali, le build prevedibili e la chiusura temporale stabile spesso contano di più rispetto alle specifiche FPGA headline isolate.
9. Perché i SoC Zynq e le piattaforme Kria SOM riducono la complessità di integrazione rispetto agli FPGA standalone?
I SoC Zynq combinano processori ARM e logica programmabile all'interno di un unico dispositivo, semplificando la comunicazione tra software e accelerazione hardware. I Kria SOM vanno oltre integrando memoria, storage di avvio, sequenziamento di alimentazione e hardware convalidato in un modulo prequalificato. Questi approcci riducono i rischi associati al routing DDR, all'affidabilità dell'avvio, al design della consegna di alimentazione e all'accensione della scheda. Di conseguenza, i team possono concentrarsi maggiormente sul comportamento dell'applicazione e meno sulle sfide di integrazione hardware a basso livello.
10. Perché il successo del deployment di AI basato su FPGA dipende fortemente dal movimento dei dati piuttosto che dalle prestazioni dell'acceleratore da solo?
Gli acceleratori AI come i DPU possono fornire un elevato throughput computazionale teorico, ma le prestazioni nel mondo reale diventano spesso limitate dalla larghezza di banda della memoria, dalla pianificazione DMA, dalla gestione dei buffer e dall'efficienza del movimento dei tensori. Pipeline di dati ottimizzate male possono privare l'acceleratore e ridurre drasticamente i FPS effettivi nonostante una forte capacità di calcolo. I sistemi FPGA AI di successo si concentrano quindi fortemente sul double-buffering, sulla topologia DMA, sulla strategia di batching, sul posizionamento della memoria e sul flusso di dati sostenuto tra sensori, memoria DDR, acceleratori e fasi di post-elaborazione.
Blog correlato
-
Quanti zeri in un milione, miliardi di trilioni?
![Quanti zeri in un milione, miliardi di trilioni?]()
29/07/2024
Milioni rappresenta 106, una figura facilmente raggruppabile rispetto agli articoli di tutti i giorni o agli stipendi annuali. Miliardi, equivalenti a... -
Foglio dati MOSFET IRLZ44N, circuito, equivalente, pinout
![Foglio dati MOSFET IRLZ44N, circuito, equivalente, pinout]()
28/08/2024
L'IRLZ44N è un MOSFET di potere N-canale ampiamente utilizzato.Rinomato per le sue eccellenti capacità di commutazione, è molto adatto per numerose... -
Temperatura della batteria troppo bassa, la ricarica si è fermata.Come risolverlo?
![Temperatura della batteria troppo bassa, la ricarica si è fermata.Come risolverlo?]()
06/10/2024
I problemi di ricarica della batteria del telefono cellulare sono comuni ma possono essere gestiti efficacemente.La temperatura svolge un ruolo import... -
BC547 Guida completa del transistor
![BC547 Guida completa del transistor]()
04/07/2024
Il transistor BC547 è comunemente usato in una varietà di applicazioni elettroniche, che vanno dagli amplificatori di segnale di base a circuiti di ... -
Guida completa al SCR (raddrizzatore controllato al silicio)
![Guida completa al SCR (raddrizzatore controllato al silicio)]()
22/04/2024
I rettificatori controllati al silicio (SCR), o tiristi, svolgono un ruolo fondamentale nella tecnologia elettronica di potenza a causa delle loro pre... -
LR621, SR621SW, 364, Equivalenti della batteria AG1 e sostituzioni
![LR621, SR621SW, 364, Equivalenti della batteria AG1 e sostituzioni]()
15/07/2024
Le batterie del pulsante LR621 e SR621SW sono prevalenti in dispositivi elettronici compatti come orologi, piccoli giocattoli, calcolatori e chiavi re... -
Una guida completa ai multiplexer e il loro ruolo nei sistemi digitali
![Una guida completa ai multiplexer e il loro ruolo nei sistemi digitali]()
20/09/2025
I multiplexer sono componenti nei sistemi digitali, progettati per incanalare più segnali di input in una singola linea di output utilizzando segnali... -
Fondamenti di circuiti di amplifica operatoria
![Fondamenti di circuiti di amplifica operatoria]()
28/12/2023
Nell'intricato mondo dell'elettronica, un viaggio nei suoi misteri ci porta invariabilmente a un caleidoscopio di componenti del circuito, sia squisit... -
Confrontare le differenze e le applicazioni di NMOS e PMO
![Confrontare le differenze e le applicazioni di NMOS e PMO]()
15/11/2024
Comprendere le differenze tra i transistor NMOS e PMOS è importante nella progettazione di circuiti efficienti.NMOS (metallo-ossido-semiconduttore di... -
CR2450 vs CR2032 Confronto: tutto ciò che devi sapere
![CR2450 vs CR2032 Confronto: tutto ciò che devi sapere]()
15/09/2025
Batterie per bottoni come CR2450 e CR2032 alimentano molti elettronici quotidiani, da orologi e telecomandi ai dispositivi medici e industriali.Sebben...










Parti calde
- AD8000YCPZ
- ISL6446IAZ
- EP4S100G5F45I1N
- CD74HC4075M96
- ADV611JST
- EPM7096LC84-15
- ISL8010Z
- AWU6605RM45Q7
- AT17LV256-10JU
- UPA1600GS-T1
- C1608CH1H681J080AA
- RD48F3300LOZDQO
- LT3690EUFE#TRPBF
- AM29LV160DB-90SC
- ML7202-001TBZ03A
- MPC860ENZQ66D4
- LT1124CS8#PBF
- TWL93004CGQWR
- 08055A8R0CAT2A
- GRM0335C1H8R9DD01D
- CGA5H2X8R1E684M115AD
- GRM1885C1H9R3CA01D
- AD7718BRZ
- IRFP4568
- SN74LVC1G07DCKR
- LD031A8R2DAB2A
- 12061A111FAT2A
- CGA6M4X7R2J683K200AE
- XC3064XL-10VQ44C
- 1MBI600V-120-50
- XC3S2000-5FGG900C
- TS26A100
- PIC16F684-I/ST
- SUD23N06-31L-T4-E3
- LTC2918CMS-B1#PBF
- TLC081IDGN
- 2DI150Z-120
- SM320F2808PZMEP
- TLV70212QDBVRQ1
- MAX4486AUA+T
- SI8620EB-B-IS
- T491C476K016AT4053
- HLG-120H-C1050A
- VI-J6P-CW
- GM5060-BE
- MC145200F
- TMP1075DSGR
- PAM2423AECADJ
- MY2K
- 252-9951-0971