- Italia
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Cos'è una NPU e come funziona nei dispositivi AI?
Catalogo

Cos'è una NPU?
Una Neural Processing Unit (NPU) è un processore specializzato progettato per gestire le attività di intelligenza artificiale in modo più efficiente rispetto a un processore generico.Il suo ruolo principale è quello di accelerare le operazioni della rete neurale utilizzate in funzionalità come il riconoscimento delle immagini, l'elaborazione vocale, il rilevamento di oggetti e l'inferenza dell'intelligenza artificiale in tempo reale.A differenza di una CPU, che è costruita per gestire molte attività informatiche diverse, una NPU si concentra sui calcoli relativi all’intelligenza artificiale.È ottimizzato per elaborare grandi quantità di dati contemporaneamente, rendendolo adatto a carichi di lavoro che richiedono un rapido riconoscimento di modelli e processi decisionali.Nei dispositivi moderni, le NPU consentono alle funzionalità di intelligenza artificiale di funzionare direttamente sull'hardware locale invece di dipendere completamente dai server cloud.Ciò consente a smartphone, fotocamere intelligenti, robot, veicoli e dispositivi edge di rispondere più rapidamente consumando meno energia.Per questo motivo, le NPU sono diventate una parte importante dei moderni sistemi intelligenti.
Architettura principale e moduli di elaborazione di una NPU
Una NPU è costituita da diversi moduli hardware specializzati che lavorano insieme per elaborare i carichi di lavoro della rete neurale in modo rapido ed efficiente.Invece di inviare ogni operazione attraverso un processore generico, il carico di lavoro è suddiviso su blocchi hardware dedicati che elaborano continuamente i dati in parallelo.Questa struttura migliora la velocità di inferenza dell'intelligenza artificiale, riduce lo spostamento non necessario di dati, riduce il consumo energetico e aiuta a mantenere un utilizzo efficiente della memoria.
Durante l'elaborazione dell'intelligenza artificiale, i dati fluiscono attraverso più fasi all'interno del processore.I dati di input entrano prima nella pipeline di calcolo, dove vengono eseguite operazioni matematiche su larga scala.I risultati intermedi passano quindi attraverso l'elaborazione di attivazione, l'accelerazione del tensore, le operazioni relative alle immagini e l'hardware di ottimizzazione della memoria prima che venga prodotto l'output finale.Poiché questi moduli operano insieme in una sequenza coordinata, la NPU può mantenere un throughput elevato anche durante l'esecuzione di modelli di reti neurali di grandi dimensioni.
Moduli di core computing e attivazione
Il motore di calcolo principale all'interno di una NPU è l'unità Multiply-Accumulate (MAC).La maggior parte dei carichi di lavoro delle reti neurali esegue ripetutamente moltiplicazioni e addizioni su set di dati molto grandi, quindi questo hardware gestisce la maggior parte dei calcoli dell'intelligenza artificiale durante l'inferenza.Quando i dati di input entrano in una rete neurale, i valori vengono moltiplicati per i valori di peso memorizzati e quindi sommati per generare nuovi output.Questo processo si ripete continuamente su molti livelli della rete neurale.
Le NPU moderne spesso contengono centinaia o migliaia di unità MAC che operano simultaneamente.Invece di calcolare un'operazione alla volta, l'hardware distribuisce i carichi di lavoro su molti percorsi di esecuzione paralleli.Grandi batch di dati AI si spostano insieme attraverso il processore, migliorando notevolmente la velocità di inferenza e mantenendo bassa la latenza.Nei sistemi di riconoscimento delle immagini, ad esempio, le unità MAC scansionano ripetutamente gruppi di pixel e combinano i valori del filtro per rilevare bordi, trame, forme e motivi.Nei modelli linguistici, lo stesso hardware esegue operazioni su vettori e matrici su larga scala per elaborare token e relazioni tra parole.
Una volta completati questi calcoli matematici, i risultati vengono spostati nel modulo Funzione di attivazione.Le reti neurali dipendono da funzioni di attivazione non lineare per elaborare relazioni complesse all'interno dei dati.Senza l’elaborazione dell’attivazione, la rete eseguirebbe solo semplici calcoli lineari e non potrebbe gestire in modo efficace le attività avanzate di intelligenza artificiale.
Questo modulo esegue funzioni come ReLU, Sigmoid e Tanh direttamente nell'hardware.I valori in ingresso vengono rapidamente trasformati in base alla regola di attivazione selezionata.ReLU, ad esempio, rimuove i valori negativi preservando gli output positivi, aiutando la rete a concentrarsi su segnali di funzionalità più forti durante l'inferenza.Poiché l'elaborazione dell'attivazione avviene ripetutamente su ogni livello della rete neurale, l'hardware di accelerazione dedicato aiuta a ridurre i ritardi e impedisce il sovraccarico delle unità di calcolo principali.
Moduli di elaborazione dati tensoriali e spaziali
Le NPU includono anche hardware specializzato per la gestione delle operazioni tensoriali e dell'elaborazione dei dati spaziali.Quasi tutti i modelli di intelligenza artificiale moderni si basano su tensori, che sono strutture di dati multidimensionali utilizzate per organizzare le informazioni su dimensioni quali larghezza, altezza, canali, livelli di funzionalità e batch.Grandi quantità di dati tensoriali si spostano continuamente tra gli strati della rete neurale durante l'inferenza.
La Tensor Acceleration Unit elabora queste strutture tensoriali direttamente nell'hardware.Operazioni come la moltiplicazione, il rimodellamento, la trasformazione e l'accumulo dei tensori vengono eseguite molto più velocemente rispetto ai processori generici.Questa accelerazione dedicata diventa particolarmente importante nelle architetture dei trasformatori, nei sistemi di visione artificiale, nei modelli linguistici di grandi dimensioni e nelle applicazioni di intelligenza artificiale in tempo reale che richiedono un throughput molto elevato.
Oltre all'elaborazione tensoriale, le NPU contengono anche moduli progettati per operazioni di dati spaziali e 2D comunemente utilizzati nei carichi di lavoro di immagini e video.I sistemi di visione artificiale ridimensionano, riorganizzano, filtrano e spostano costantemente grandi quantità di dati di pixel prima che inizi un'analisi più approfondita dell'intelligenza artificiale.Gestire queste attività separatamente migliora l'efficienza e riduce la pressione sul motore di elaborazione principale.
Durante l'elaborazione delle immagini, l'hardware gestisce operazioni come il downsampling, lo spostamento della mappa delle caratteristiche, la copia delle immagini, il ridimensionamento, il ritaglio e il trasferimento dei dati spaziali.Ad esempio, il video ad alta risoluzione catturato da una telecamera può essere ridimensionato e riorganizzato prima di entrare nella pipeline della rete neurale.Ciò riduce il carico computazionale preservando importanti informazioni visive necessarie per il rilevamento degli oggetti e l'analisi della scena.
Moduli di ottimizzazione della memoria e compressione dei dati
I moderni modelli di intelligenza artificiale richiedono grandi quantità di memoria per archiviare pesi, tensori e dati intermedi della rete neurale.Il trasferimento costante di queste informazioni tra la memoria e l'hardware del computer aumenta l'utilizzo della larghezza di banda, la latenza e il consumo energetico.Per ridurre questo sovraccarico, le NPU includono moduli dedicati di compressione e decompressione dei dati.
Prima che i dati vengano archiviati in memoria, i modelli ripetuti e i valori di peso vengono compressi in formati più piccoli.Durante l'esecuzione, le informazioni compresse vengono rapidamente ripristinate e inviate direttamente alla pipeline di elaborazione.Ciò riduce il traffico di memoria e consente a più dati AI di rimanere nella memoria locale ad alta velocità più vicina al processore.
I metodi di compressione avanzati possono spesso ridurre le dimensioni del modello più volte mantenendo quasi la stessa precisione di inferenza.Ciò diventa particolarmente importante negli smartphone, nei sistemi integrati, nelle fotocamere intelligenti, nell’elettronica indossabile e in altri dispositivi IA all’avanguardia in cui la capacità di memoria e l’efficienza energetica sono limitate.
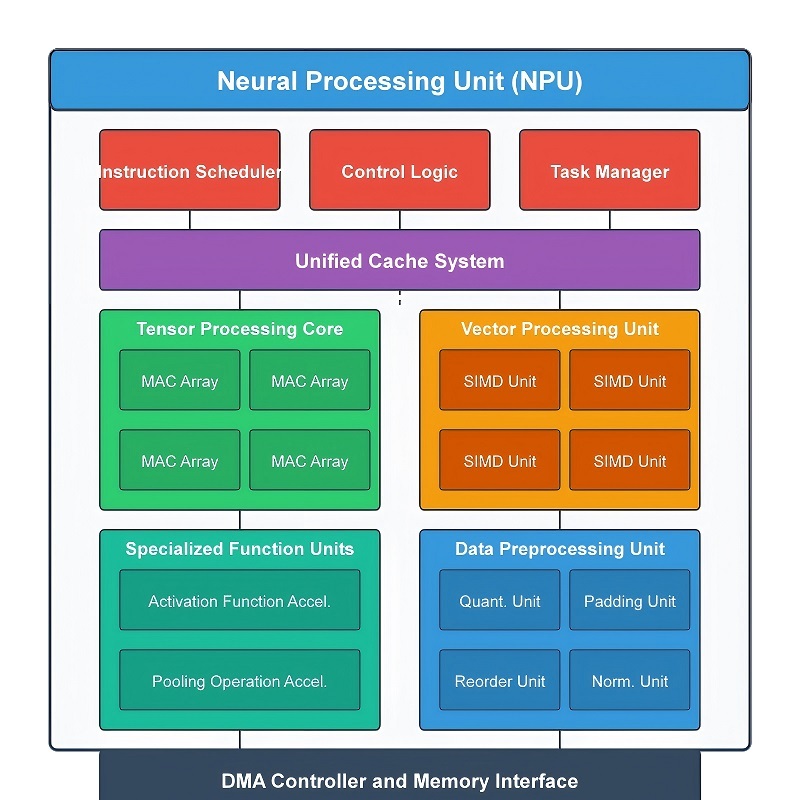
Come questi moduli funzionano insieme
Le prestazioni di una NPU non si basano su un singolo blocco hardware.La sua efficienza deriva dal modo in cui tutti i moduli di elaborazione operano insieme come una pipeline coordinata.
Un tipico carico di lavoro dell’intelligenza artificiale inizia con calcoli matematici su larga scala all’interno delle unità MAC.I risultati intermedi passano quindi attraverso l’elaborazione di attivazione per introdurre un comportamento non lineare nella rete neurale.L'hardware di accelerazione tensore organizza ed elabora continuamente dati multidimensionali lungo tutta la pipeline, mentre i moduli di elaborazione spaziale gestiscono le operazioni relative a immagini e video.Allo stesso tempo, l'hardware di compressione riduce il sovraccarico del trasferimento di memoria in background.
Poiché queste operazioni vengono eseguite simultaneamente su percorsi hardware dedicati, la NPU può elaborare grandi carichi di lavoro AI con throughput elevato, latenza inferiore ed efficienza energetica di gran lunga migliore rispetto ai processori tradizionali.
NPU negli smartphone e nell'intelligenza artificiale mobile
Gli smartphone moderni gestiscono un numero enorme di operazioni ogni secondo.Un telefono può sbloccarsi con il riconoscimento facciale, aprire la fotocamera, elaborare foto, tradurre parlato ed eseguire applicazioni assistite dall'intelligenza artificiale quasi istantaneamente.Per supportare questo livello di prestazioni all'interno di dispositivi mobili sottili con capacità della batteria limitata, gli smartphone si affidano ad architetture System-on-Chip (SoC) altamente integrate.
All'interno del SoC, più processori lavorano insieme e ciascun processore è ottimizzato per un carico di lavoro diverso.La CPU gestisce il controllo del sistema, le applicazioni e le attività informatiche generali.La GPU gestisce il rendering grafico, i giochi e l'elaborazione visiva.La NPU (Neural Processing Unit) si concentra specificamente sul calcolo dell'intelligenza artificiale.
Invece di instradare i carichi di lavoro della rete neurale attraverso la CPU o la GPU, gli smartphone indirizzano molte attività di intelligenza artificiale alla NPU, dove l’hardware è ottimizzato per una rapida elaborazione parallela dell’intelligenza artificiale.Questa separazione migliora l'efficienza perché ogni processore gestisce il tipo di carico di lavoro per cui è stato progettato.Di conseguenza, gli smartphone possono eseguire operazioni di intelligenza artificiale avanzate con tempi di risposta più rapidi, latenza inferiore e migliore efficienza energetica.
Come le NPU hanno cambiato l'intelligenza artificiale degli smartphone
Prima che le NPU mobili diventassero comuni, molte funzionalità dell’intelligenza artificiale degli smartphone dipendevano fortemente dal cloud computing.Attività come il riconoscimento vocale, la traduzione linguistica, il miglioramento delle immagini e gli assistenti intelligenti spesso richiedevano il caricamento dei dati su server remoti per l'elaborazione prima che i risultati venissero restituiti al dispositivo.Ciò ha creato ritardi, aumento del traffico di rete e sollevato problemi di privacy.
L'introduzione di NPU mobili dedicate ha cambiato in modo significativo questo flusso di lavoro.I modelli di intelligenza artificiale ora potrebbero essere eseguiti direttamente sullo smartphone stesso, consentendo a molte operazioni di essere eseguite localmente in tempo reale invece di dipendere interamente da server esterni.
Questo cambiamento ha fornito diversi vantaggi importanti:
• Minore latenza perché i dati non necessitano più di una comunicazione cloud costante
• Tempi di risposta dell'IA più rapidi durante le operazioni in tempo reale
• Migliore protezione della privacy poiché i dati sensibili possono rimanere sul dispositivo
• Consumo energetico ridotto grazie all'hardware ottimizzato specificatamente per i carichi di lavoro IA
• Prestazioni AI più stabili anche con connessioni Internet deboli o non disponibili
Man mano che le NPU mobili sono diventate più potenti, gli smartphone hanno iniziato a eseguire funzionalità AI avanzate continuamente in background senza ritardi evidenti durante l’uso quotidiano.
Come gli smartphone utilizzano le NPU nelle operazioni reali
Fotografia AI ed elaborazione delle immagini
Uno degli usi più visibili delle NPU mobili è la fotografia AI.Le moderne fotocamere degli smartphone non si affidano più solo ai sensori di immagine e ai tradizionali algoritmi di elaborazione delle immagini.I modelli AI ora analizzano continuamente i dati delle immagini mentre la fotocamera è in funzione.
Quando si apre l'app della fotocamera, lo smartphone inizia immediatamente a elaborare il flusso di immagini in arrivo fotogramma per fotogramma.La NPU analizza le condizioni di illuminazione, i confini degli oggetti, i dettagli del viso, i colori, le trame e gli schemi di movimento in tempo reale.Sulla base di questa analisi, il sistema regola l'esposizione, il bilanciamento del bianco, le impostazioni HDR, la nitidezza e il contrasto quasi istantaneamente prima che l'immagine venga catturata.
Nella fotografia in condizioni di scarsa illuminazione, la NPU combina più fotogrammi di immagini insieme per migliorare la luminosità riducendo al contempo il rumore visivo.Durante la fotografia di ritratto, il processore separa i soggetti in primo piano dalle aree dello sfondo e applica effetti di profondità in modo più accurato attorno ai bordi come capelli, occhiali e contorni dei vestiti.
Anche il riconoscimento delle scene dipende fortemente dalla NPU.Il processore confronta i modelli di immagini con modelli di intelligenza artificiale addestrati per identificare ambienti come cibo, paesaggi, animali domestici, documenti, tramonti o scene notturne.Una volta riconosciuta, la fotocamera regola automaticamente le impostazioni per ottimizzare la qualità dell'immagine.
Poiché questi calcoli vengono eseguiti direttamente sullo smartphone, la fotografia tramite intelligenza artificiale sembra quasi istantanea, anche se grandi quantità di calcoli della rete neurale avvengono continuamente in background.
Riconoscimento vocale e assistenti AI
Anche gli assistenti vocali e le funzionalità legate al parlato fanno molto affidamento sull’accelerazione dell’intelligenza artificiale locale.Quando un utente parla allo smartphone, il microfono cattura segnali audio grezzi che devono essere puliti, separati e convertiti in schemi vocali riconoscibili.
La NPU elabora continuamente il flusso audio identificando i fonemi, filtrando il rumore di fondo e confrontando i modelli sonori con i modelli di riconoscimento vocale.L'elaborazione dell'intelligenza artificiale locale consente di rilevare quasi istantaneamente le parole di attivazione e i comandi vocali comuni senza trasmettere costantemente registrazioni audio ai server cloud.
Ciò migliora la reattività per attività quali:
• Comandi vocali
• Trascrizione vocale in tempo reale
• Traduzione linguistica
• Interazione con l'assistente AI
• Miglioramento delle chiamate AI
• Soppressione del rumore durante le videochiamate
Poiché gran parte dell'elaborazione avviene direttamente sul dispositivo, l'interazione vocale rimane più fluida anche in condizioni di rete instabili.
Gioco AI e ottimizzazione del sistema in tempo reale
Gli smartphone moderni utilizzano le NPU anche per l'ottimizzazione del gioco e la gestione intelligente del sistema.Durante il gioco, i modelli di intelligenza artificiale monitorano in tempo reale la richiesta di rendering dei fotogrammi, il comportamento del carico di lavoro, le condizioni termiche, i modelli di input touch e l'utilizzo della batteria.
Il sistema può regolare dinamicamente i carichi di lavoro della GPU, ottimizzare l'allocazione della potenza, stabilizzare i frame rate e ridurre il surriscaldamento durante le lunghe sessioni di gioco.Alcuni smartphone utilizzano anche tecniche di upscaling AI e previsione del movimento per migliorare la fluidità visiva mantenendo un consumo energetico inferiore.
Al di fuori dei giochi, la NPU aiuta a ottimizzare le applicazioni in background, la gestione della batteria, le interazioni predittive dell'utente e la pianificazione delle attività in base ai modelli di utilizzo del dispositivo.
Evoluzione delle NPU mobili
Lo sviluppo di NPU mobili ha subito una rapida accelerazione man mano che i carichi di lavoro dell’intelligenza artificiale degli smartphone sono diventati più avanzati e impegnativi dal punto di vista computazionale.
|
Periodo |
Sviluppo NPU mobile |
|
2017: prime NPU mobili commerciali |
Huawei ha introdotto uno dei primi smartphone commerciali
NPU tramite il processore Kirin 970.Ciò ha segnato un importante cambiamento verso
accelerazione dell’intelligenza artificiale su larga scala all’interno degli smartphone consumer.Invece di
basandosi principalmente su CPU e GPU per attività di intelligenza artificiale, smartphone ora inclusi
hardware AI dedicato direttamente all'interno dell'architettura SoC. |
|
2018: espansione dell'intelligenza artificiale sul dispositivo |
Apple ha introdotto il Neural Engine all'interno dell'A12 Bionic
chip, miglioramento dell'elaborazione AI per il riconoscimento facciale, computazionale
fotografia e funzionalità mobili intelligenti.L'intelligenza artificiale sul dispositivo è diventata una delle principali
concentrarsi sullo sviluppo di smartphone di punta. |
|
2019-2020: integrazione dell’intelligenza artificiale a livello di settore |
I principali produttori di chip tra cui Qualcomm, Samsung e
MediaTek ha iniziato a integrare acceleratori AI dedicati nei dispositivi mobili di punta
processori.Le prestazioni dell’intelligenza artificiale hanno iniziato a diventare un importante fattore competitivo nel settore
progettazione dell'hardware dello smartphone. |
|
2021-2023: l’elaborazione dell’intelligenza artificiale diventa un punto di riferimento fondamentale |
I produttori di smartphone confrontano sempre più NPU
prestazioni insieme alle prestazioni di CPU e GPU.Le NPU sono diventate centrali
fotografia computazionale, intelligenza artificiale vocale, miglioramento video, ottimizzazione della batteria,
e funzionalità di sistema intelligenti. |
|
2024-2025 — Grandi modelli di intelligenza artificiale in esecuzione sugli smartphone |
Le moderne NPU mobili hanno acquisito una potenza di elaborazione sufficiente per
supportare modelli AI più grandi direttamente su smartphone e dispositivi edge.Più intelligenza artificiale
i carichi di lavoro potrebbero ora essere eseguiti localmente senza dipendere fortemente dal cloud
infrastruttura, migliorando sia la reattività che la privacy. |
Confronto delle attuali NPU mobili mainstream
I moderni processori per smartphone di punta includono ora architetture NPU altamente avanzate ottimizzate per l'inferenza AI in tempo reale, un throughput elevato e una migliore efficienza energetica.
|
Processore mobile |
Caratteristiche dell'NPU |
|
Apple A17 Pro |
Include un motore neurale a 26 core progettato per una velocità elevata
elaborazione AI sul dispositivo.L'architettura migliora la fotografia AI, la voce
riconoscimento e funzionalità di sistema intelligenti in tempo reale su tutti i dispositivi Apple. |
|
Qualcomm Snapdragon 8 Gen 3 |
Utilizza un processore Hexagon AI aggiornato e ottimizzato per
intelligenza artificiale generativa, accelerazione della rete neurale, elaborazione avanzata delle immagini e
carichi di lavoro IA mobili efficienti. |
|
MediaTek Dimensity 9300 |
Include un'APU (unità di elaborazione AI) di sesta generazione con
importanti miglioramenti nella velocità di inferenza dell’intelligenza artificiale e nell’elaborazione dell’intelligenza artificiale in tempo reale
funzionalità per smartphone e dispositivi edge. |
|
Samsung Exynos 2400 |
Dispone di una NPU mobile di nuova generazione focalizzata sulla velocità
Elaborazione AI sul dispositivo per la fotografia computazionale, sistema intelligente
operazioni e applicazioni avanzate di intelligenza artificiale mobile. |
NPU vs GPU vs CPU: differenze chiave nell'elaborazione dell'intelligenza artificiale
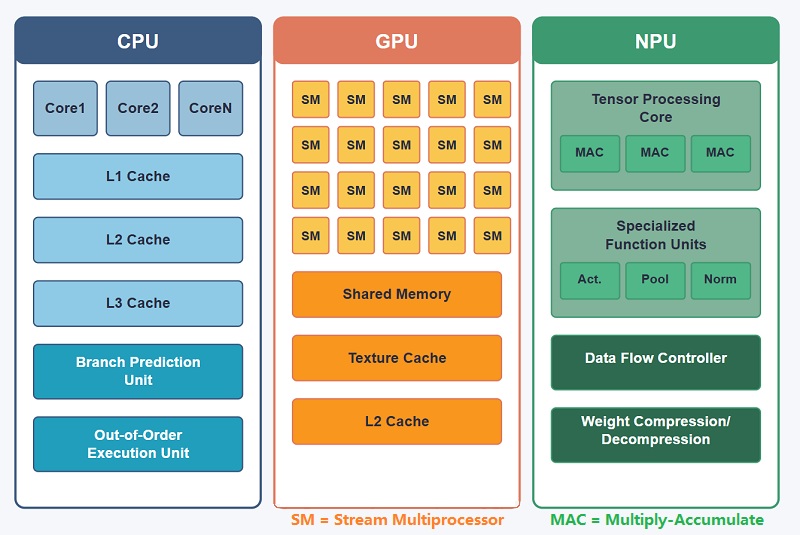
Sia le GPU che le NPU sono progettate per elaborare grandi quantità di dati in parallelo, ma sono state costruite per scopi molto diversi.Una GPU è stata originariamente sviluppata per il rendering grafico, mentre una NPU è stata creata appositamente per il calcolo della rete neurale e l'inferenza dell'intelligenza artificiale. A causa di questa differenza negli obiettivi di progettazione, i due processori gestiscono i carichi di lavoro dell'intelligenza artificiale in modi molto diversi.Le GPU possono eseguire modelli di intelligenza artificiale in modo efficace, soprattutto nei sistemi di addestramento su larga scala, ma comportano ancora gran parte della complessità di un processore grafico.Le NPU semplificano molte di queste operazioni concentrandosi quasi interamente sul calcolo relativo all’intelligenza artificiale.
|
Caratteristica |
CPU
(Central Processing Unit) |
GPU
(Graphics Processing Unit) |
NPU
(Unità di elaborazione neurale) |
|
Scopo principale |
Uso generale
computing and system control |
Parallelo
graphics and high-performance computation |
Inferenza dell'intelligenza artificiale e
neural network acceleration |
|
Carico di lavoro primario |
Operativo
systems, applications, multitasking |
Grafica
rendering, AI training, scientific computing |
elaborazione dell'intelligenza artificiale,
tensor operations, deep learning inference |
|
Stile di elaborazione |
Sequenziale
elaborazione |
Parallelo enorme
elaborazione |
Ottimizzato per l'intelligenza artificiale
elaborazione parallela |
|
Progettazione del nucleo |
Pochi potenti e
nuclei flessibili |
Migliaia di
core di esecuzione parallela |
IA specializzata
unità di accelerazione |
|
Prestazioni dell'IA |
Moderato |
Alto |
Molto alto per l'intelligenza artificiale
inferenza |
|
Matrice
Velocità di moltiplicazione |
Limitato |
Veloce |
Altamente ottimizzato |
|
Tensore
Elaborazione |
Basato su software |
Supportato
attraverso l'accelerazione GPU |
Tensore dedicato
hardware di accelerazione |
|
Efficienza energetica |
Più basso per l'IA
carichi di lavoro |
Da moderato ad alto
consumo di energia |
Altamente potente
efficiente |
|
Generazione di calore |
Moderato |
Alto sotto pesante
carichi di lavoro |
Inferiore durante l'IA
inferenza |
|
Larghezza di banda della memoria
Utilizzo |
Moderato |
Molto alto |
Ottimizzato e
ridotto |
|
Latenza nell'intelligenza artificiale
Compiti |
Più in alto |
Moderato |
Molto basso |
|
IA in tempo reale
Capacità |
Limitato |
Bene |
Eccellente |
|
Il meglio per l'intelligenza artificiale
Formazione |
Non è l'ideale |
Eccellente |
Limitato rispetto
alle GPU |
|
Il meglio per l'intelligenza artificiale
Inferenza |
Carichi di lavoro di base |
Ad alte prestazioni
inferenza |
Ottimizzato
inferenza in tempo reale |
|
Comune
Applicazioni |
PC, server,
sistemi operativi |
Giochi, intelligenza artificiale
training, rendering, simulations |
smartphone,
edge AI, robotics, smart cameras |
|
Dipendenza da
IA sulla nuvola |
Più in alto |
Moderato |
Inferiore a causa di
accelerazione dell'IA locale |
|
Batteria
Efficiency in Mobile Devices |
Più in basso |
Moderato |
Alto |
|
Dispositivi tipici |
computer,
laptop, server |
PC da gioco, intelligenza artificiale
server, postazioni di lavoro |
Smartphone, IoT
devices, edge AI hardware |
|
Costo e
Complessità |
Uso generale
architettura |
Complesso
high-performance architecture |
Specializzato
Architettura incentrata sull'intelligenza artificiale |
|
Vantaggio principale |
Flessibilità e
gestione del sistema |
Su larga scala
calcolo parallelo |
Veloce e
efficient local AI processing |
Unità di elaborazione specializzate nell'informatica moderna
A parte la NPU, i moderni sistemi informatici utilizzano molti tipi diversi di processori perché nessuna singola architettura può gestire in modo efficiente ogni carico di lavoro.Alcuni processori si concentrano sul controllo del sistema, alcuni sono specializzati nel rendering grafico, mentre altri sono ottimizzati per l'accelerazione dell'intelligenza artificiale, il networking, il calcolo scientifico o il controllo integrato.
All’interno dei moderni smartphone, server, sistemi industriali, piattaforme robotiche, veicoli e dispositivi edge AI, più unità di elaborazione spesso lavorano insieme contemporaneamente.Ogni processore gestisce il tipo di carico di lavoro per il quale è stato specificamente progettato, migliorando le prestazioni, l'efficienza energetica e la reattività in tempo reale nei moderni ambienti informatici.
CPU: unità di elaborazione centrale
Una CPU (Central Processing Unit) è il controller principale della maggior parte dei sistemi informatici.Gestisce i sistemi operativi, le applicazioni, il coordinamento della memoria, la pianificazione delle attività e la comunicazione tra i componenti hardware.
Le CPU sono altamente flessibili e possono gestire in modo affidabile molti carichi di lavoro diversi, rendendole essenziali in computer, smartphone, server e sistemi embedded.Tuttavia, sono meno efficienti per carichi di lavoro di intelligenza artificiale parallela su larga scala rispetto ai processori più specializzati.
GPU: unità di elaborazione grafica
Una GPU (Graphics Processing Unit) è ottimizzata per l'elaborazione parallela su larga scala.L'architettura contiene molti core di esecuzione in grado di gestire migliaia di operazioni contemporaneamente.
Le GPU sono state originariamente sviluppate per il rendering grafico, ma ora sono ampiamente utilizzate per l'addestramento dell'intelligenza artificiale, la simulazione scientifica, l'elaborazione video e il calcolo ad alte prestazioni grazie alla loro forte capacità di calcolo parallelo.
TPU: unità di elaborazione tensore
Una TPU (Tensor Processing Unit) è ottimizzata per carichi di lavoro AI basati su tensori e accelerazione del deep learning su larga scala.Questi processori sono progettati principalmente per infrastrutture AI cloud e ambienti di machine learning di data center.
I TPU sono altamente efficaci per:
• Formazione sull'apprendimento profondo
• Grandi modelli di IA
• Calcolo tensoriale
• Servizi di intelligenza artificiale nel cloud
• Accelerazione IA ad alto rendimento
FPGA: elaborazione hardware riconfigurabile
Un FPGA (Field-Programmable Gate Array) utilizza blocchi logici programmabili che possono essere configurati per attività specifiche dopo la produzione.A differenza delle architetture di processore fisse, gli FPGA consentono di personalizzare la funzione hardware stessa.
Gli FPGA sono ampiamente utilizzati in:
• Sistemi di comunicazione
• Elettronica automobilistica
• Automazione industriale
• Sistemi aerospaziali
• Informatica perimetrale
• Dispositivi medici
DPU: Unità di elaborazione dati
Una DPU (unità di elaborazione dati) è ottimizzata per carichi di lavoro incentrati sui dati all'interno dell'infrastruttura cloud e dei sistemi di rete.Le DPU aiutano a ridurre il carico di lavoro della CPU accelerando lo spostamento dei dati, le operazioni di archiviazione, la crittografia e la gestione del traffico di rete.
Questi processori sono comunemente usati in:
• Centri dati
• Calcolo della nuvola
• Rete ad alta velocità
• Accelerazione dell'archiviazione
• Infrastruttura server
VPU: Unità di elaborazione della visione
Una VPU (Vision Processing Unit) è specializzata nella visione artificiale e nell'elaborazione dell'intelligenza artificiale basata su immagini.Le VPU accelerano carichi di lavoro come riconoscimento facciale, rilevamento di oggetti, tracciamento del movimento e analisi video.
Le VPU si trovano comunemente in:
• Fotocamere intelligenti
• Sistemi di sorveglianza
• Robotica
• Veicoli autonomi
• Sistemi AR/VR
• Dispositivi di visione Edge AI
IPU: Unità di elaborazione delle informazioni
Una IPU (Intelligence Processing Unit) è progettata per carichi di lavoro di intelligenza artificiale e machine learning altamente paralleli.L'architettura si concentra sul miglioramento dell'efficienza del flusso di dati durante l'esecuzione della rete neurale su larga scala.
Le IPU vengono utilizzate per:
• Accelerazione dell'apprendimento automatico
• Riconoscimento di modelli
• Inferenza dell'IA
• Elaborazione tensoriale parallela
• Ricerca avanzata sull'intelligenza artificiale
BPU: Unità di elaborazione del cervello
Una BPU (Brain Processing Unit) è ottimizzata per i sistemi di intelligenza artificiale e edge intelligence integrati.Questi processori si concentrano sull'inferenza AI locale veloce con un consumo energetico inferiore.
Le BPU sono comunemente utilizzate in:
• Sistemi di rilevamento intelligenti
• Robotica
• Hardware IA Edge
• Sistemi di rilevamento del movimento
• Piattaforme autonome
HPU: Unità di elaborazione olografica
Una HPU (Holographic Processing Unit) è progettata per sistemi di calcolo olografico, realtà mista e analisi spaziale.
Le HPU aiutano il processo:
• Mappatura ambientale
• Tracciamento del movimento
• Fusione dei sensori
• Interazione spaziale in tempo reale
• Ambienti AR/VR
MPU e MCU: elaborazione del controllo integrato
Le MPU (unità microprocessore) e le MCU (unità microcontrollore) sono ampiamente utilizzate nei sistemi embedded e nell'elettronica a bassa potenza.
Le MPU sono comunemente utilizzate nei sistemi informatici embedded che richiedono controllo a livello di sistema operativo, mentre le MCU integrano core del processore, memoria e controllo di input/output in un chip compatto per attività dedicate a basso consumo.
Questi processori si trovano comunemente in:
• Dispositivi IoT
• Controllori industriali
• Elettronica automobilistica
• Elettrodomestici
• Sistemi embedded portatili
APU: unità di elaborazione accelerata
Un'APU (Accelerated Processing Unit) combina le funzionalità CPU e GPU all'interno di un unico pacchetto processore.Questa integrazione migliora l'efficienza energetica, riduce le dimensioni dell'hardware e consente ai carichi di lavoro di elaborazione e grafica di condividere le risorse di sistema in modo più efficiente.
Le APU sono comunemente utilizzate in:
• Computer portatili
• Mini PC
• Sistemi di gioco entry-level
• Dispositivi multimediali
• Piattaforme informatiche portatili
Perché i sistemi moderni utilizzano più processori specializzati
I moderni sistemi informatici raramente si basano su un'architettura a processore singolo.I dispositivi combinano invece più processori specializzati perché carichi di lavoro diversi richiedono metodi di elaborazione diversi.
Ad esempio, un sistema moderno può utilizzare:
• CPU per il controllo del sistema
• GPU per grafica e calcolo parallelo
• NPU per l'inferenza dell'IA
• VPU per la visione artificiale
• DPU per il networking e lo spostamento dei dati
• MCU per attività di controllo integrate
Distribuendo i carichi di lavoro su hardware dedicato, i sistemi moderni ottengono prestazioni migliori, minore latenza, migliore efficienza energetica ed elaborazione in tempo reale più efficace negli ambienti di intelligenza artificiale, grafica, rete e elaborazione incorporata.
Conclusione
Le NPU stanno diventando essenziali nell’informatica moderna perché consentono l’esecuzione locale, rapida ed efficiente delle attività di intelligenza artificiale senza dipendere fortemente dall’elaborazione cloud.La loro architettura ottimizzata riduce la latenza, il consumo energetico, lo spostamento della memoria e la generazione di calore, rendendoli preziosi per smartphone, robotica, dispositivi sanitari, automazione industriale, case intelligenti, sistemi autonomi e piattaforme IA edge.Man mano che i modelli di intelligenza artificiale diventano più grandi e complessi, le future NPU continueranno a migliorare attraverso architetture più intelligenti, elaborazione a bassa precisione, elaborazione in memoria, supporto locale di modelli di grandi dimensioni, progettazione avanzata di semiconduttori e funzionalità di sicurezza dell’intelligenza artificiale più forti.
Domande frequenti [FAQ]
1. Perché le NPU sono più efficienti delle CPU per i carichi di lavoro delle reti neurali?
Le NPU sono più efficienti perché il loro hardware è progettato specificamente per il calcolo dell’intelligenza artificiale anziché per l’elaborazione generica.Una CPU gestisce molte attività di sistema diverse in sequenza, mentre una NPU si concentra principalmente su operazioni tensoriali, moltiplicazione di matrici, convoluzione ed elaborazione parallela della rete neurale.Ciò consente alle NPU di completare l'inferenza dell'IA più velocemente utilizzando meno energia e generando meno calore.
2. In che modo l'elaborazione parallela migliora le prestazioni della NPU durante l'inferenza dell'intelligenza artificiale?
Le NPU dividono i carichi di lavoro dell’intelligenza artificiale in molte operazioni più piccole che vengono eseguite simultaneamente su più unità di calcolo.Invece di attendere il completamento di un’istruzione prima di avviarne un’altra, grandi quantità di dati della rete neurale si muovono attraverso il processore in parallelo.Ciò migliora significativamente il throughput e riduce la latenza durante carichi di lavoro come il riconoscimento delle immagini, l'elaborazione vocale e il rilevamento di oggetti in tempo reale.
3. Perché il calcolo a bassa precisione è importante nelle moderne NPU?
Molti modelli di intelligenza artificiale non richiedono una precisione numerica estremamente elevata per produrre risultati accurati.Le NPU utilizzano formati come INT8 e FP16 per ridurre l'utilizzo della memoria e il sovraccarico computazionale.L'elaborazione a precisione inferiore consente di completare più operazioni in meno tempo, migliorando al contempo l'efficienza energetica e mantenendo elevate prestazioni di inferenza dell'IA.
4. In che modo le NPU riducono i colli di bottiglia nel trasferimento di memoria rispetto alle GPU?
Le NPU collocano la memoria e l'hardware di calcolo più vicini all'interno dell'architettura del processore.Invece di trasferire ripetutamente grandi quantità di dati tensoriali tra la memoria esterna e i core di elaborazione, molte operazioni intermedie rimangono vicino alle unità di esecuzione.Ciò accorcia i percorsi dei dati, riduce l'utilizzo della larghezza di banda, abbassa la latenza e migliora l'efficienza energetica complessiva.
5. Perché le NPU stanno diventando utili negli smartphone e nei dispositivi edge AI?
I dispositivi moderni richiedono un'elaborazione AI locale veloce con un basso consumo energetico e una latenza minima.Le NPU consentono agli smartphone e ai sistemi edge di eseguire attività di intelligenza artificiale come riconoscimento facciale, fotografia AI, interazione vocale e rilevamento di oggetti direttamente sul dispositivo senza dipendere pesantemente dai server cloud.Ciò migliora la reattività, la privacy e l'efficienza della batteria.
6. In che modo le unità MAC contribuiscono all'accelerazione NPU?
Le unità Multiply-Accumulate (MAC) gestiscono le operazioni ripetute di moltiplicazione e addizione utilizzate nelle reti neurali.Le moderne NPU contengono centinaia o migliaia di unità MAC che funzionano simultaneamente, consentendo di elaborare grandi carichi di lavoro AI molto più velocemente rispetto ai tradizionali processori sequenziali.
7. Perché i moderni sistemi di intelligenza artificiale utilizzano sia GPU che NPU invece di fare affidamento su un solo tipo di processore?
GPU e NPU sono ottimizzate per carichi di lavoro diversi.Le GPU eccellono nell'addestramento dell'intelligenza artificiale su larga scala, nel rendering grafico e nel calcolo parallelo ad alte prestazioni, mentre le NPU sono ottimizzate per l'inferenza dell'intelligenza artificiale a basso consumo e l'elaborazione locale in tempo reale.L'utilizzo contemporaneo di entrambi i processori consente ai sistemi di bilanciare flessibilità, prestazioni ed efficienza energetica.
8. In che modo le NPU migliorano l'elaborazione dell'intelligenza artificiale in tempo reale nella robotica e nei sistemi autonomi?
La robotica e i sistemi autonomi elaborano continuamente l’input della telecamera, la mappatura ambientale, i dati dei sensori e l’analisi del movimento.Le NPU accelerano questi carichi di lavoro localmente con bassa latenza, consentendo ai sistemi di reagire rapidamente durante la navigazione, il rilevamento degli ostacoli, il riconoscimento dei pedoni e il processo decisionale in tempo reale.
9. Perché l’intelligenza artificiale on-device sta diventando sempre più importante per il futuro sviluppo delle NPU?
L’intelligenza artificiale sul dispositivo riduce la dipendenza dal cloud computing consentendo l’esecuzione diretta dei modelli di intelligenza artificiale sull’hardware locale.Ciò migliora la privacy, riduce l'utilizzo della larghezza di banda della rete e consente risposte più rapide in tempo reale.Si prevede che le future NPU supporteranno modelli di IA locali più ampi, elaborazione di IA multimodale e carichi di lavoro di IA generativa avanzata direttamente all’interno dei dispositivi di consumo e industriali.
10. In che modo le future architetture NPU potrebbero cambiare l’efficienza dell’hardware AI?
Le future NPU utilizzeranno probabilmente un’allocazione più intelligente del carico di lavoro, elaborazione sparsa, elaborazione in memoria, architetture chiplet e controllo di precisione adattivo per migliorare l’efficienza.Queste tecnologie mirano a ridurre i calcoli non necessari, abbassare il consumo energetico e aumentare la produttività, supportando al contempo modelli di intelligenza artificiale più grandi e avanzati su dispositivi edge, robotica, sistemi industriali ed elettronica di consumo intelligente.
Blog correlato
-
Quanti zeri in un milione, miliardi di trilioni?
![Quanti zeri in un milione, miliardi di trilioni?]()
29/07/2024
Milioni rappresenta 106, una figura facilmente raggruppabile rispetto agli articoli di tutti i giorni o agli stipendi annuali. Miliardi, equivalenti a... -
Foglio dati MOSFET IRLZ44N, circuito, equivalente, pinout
![Foglio dati MOSFET IRLZ44N, circuito, equivalente, pinout]()
28/08/2024
L'IRLZ44N è un MOSFET di potere N-canale ampiamente utilizzato.Rinomato per le sue eccellenti capacità di commutazione, è molto adatto per numerose... -
Temperatura della batteria troppo bassa, la ricarica si è fermata.Come risolverlo?
![Temperatura della batteria troppo bassa, la ricarica si è fermata.Come risolverlo?]()
06/10/2024
I problemi di ricarica della batteria del telefono cellulare sono comuni ma possono essere gestiti efficacemente.La temperatura svolge un ruolo import... -
BC547 Guida completa del transistor
![BC547 Guida completa del transistor]()
04/07/2024
Il transistor BC547 è comunemente usato in una varietà di applicazioni elettroniche, che vanno dagli amplificatori di segnale di base a circuiti di ... -
Guida completa al SCR (raddrizzatore controllato al silicio)
![Guida completa al SCR (raddrizzatore controllato al silicio)]()
22/04/2024
I rettificatori controllati al silicio (SCR), o tiristi, svolgono un ruolo fondamentale nella tecnologia elettronica di potenza a causa delle loro pre... -
LR621, SR621SW, 364, Equivalenti della batteria AG1 e sostituzioni
![LR621, SR621SW, 364, Equivalenti della batteria AG1 e sostituzioni]()
15/07/2024
Le batterie del pulsante LR621 e SR621SW sono prevalenti in dispositivi elettronici compatti come orologi, piccoli giocattoli, calcolatori e chiavi re... -
Fondamenti di circuiti di amplifica operatoria
![Fondamenti di circuiti di amplifica operatoria]()
28/12/2023
Nell'intricato mondo dell'elettronica, un viaggio nei suoi misteri ci porta invariabilmente a un caleidoscopio di componenti del circuito, sia squisit... -
Confrontare le differenze e le applicazioni di NMOS e PMO
![Confrontare le differenze e le applicazioni di NMOS e PMO]()
15/11/2024
Comprendere le differenze tra i transistor NMOS e PMOS è importante nella progettazione di circuiti efficienti.NMOS (metallo-ossido-semiconduttore di... -
Una guida completa ai multiplexer e il loro ruolo nei sistemi digitali
![Una guida completa ai multiplexer e il loro ruolo nei sistemi digitali]()
20/09/2025
I multiplexer sono componenti nei sistemi digitali, progettati per incanalare più segnali di input in una singola linea di output utilizzando segnali... -
Cosa significano STD, AGM e Gel su un caricabatterie
![Cosa significano STD, AGM e Gel su un caricabatterie]()
10/07/2024
I caricabatterie tradizionali a batteria con acido piombo sono noti per la loro semplicità e affidabilità.Hanno servito il loro scopo in modo effica...










Parti calde
- GRM1885C1H331GA01J
- 12065C274KAT2A
- KIA78M12F
- RT0402BRE07187RL
- RT0603DRD07160RL
- GRM1885C1H4R6CA01D
- C2012X5R1E106M125AB
- 04025A470GAT2A
- 4608X-102-224
- 7MBR15VKC060-50
- PALCE16V8-10JCT
- CC0603JRX7R8BB823
- T350A105M035AT
- UPD78042AGF
- PMB5650VV1.1
- PTAS5112DFD
- MAX2027EUP+TD
- SPM4020T-100M-LR
- 08055A470JAQ2A
- MBM29LV160TE90TN
- SP3232EHCA-L
- GCM32ER71H475KA55K
- A40MX04-VQG80
- P89C51RC2HFA
- PM9012A-E2
- 08051C473MAT2A
- MM3113BWRE
- XC6SLX150-2FGG676I
- FOXLF024S
- MURS340T3G
- KLUDG8J1CB-B0B1
- PAM2401SCADJ
- RT0603DRD0716KL
- MSP430F6736AIPZR
- TD180N16KOF
- 06035C223JAZ2A
- GRM1555C1E511JA01D
- YMZ779-SZ
- DPF240X400NA
- AD7346ASTZ
- BQ27441DRZR-G1A
- MCP1631-E/ST
- VE-JW4-IX
- AM80A-048L-120F18
- 74LVCR162245DGGR
- MB84VD21183DA-85PBS-G
- S29GL512R10TFIR10
- EME1116AESE-DV-E
- WNM2016A-3/TR
- MMA8452Q