- Italia
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Come funzionano i dispositivi IoT: Architettura, Componenti e Fattori di Prestazione
Catalogo
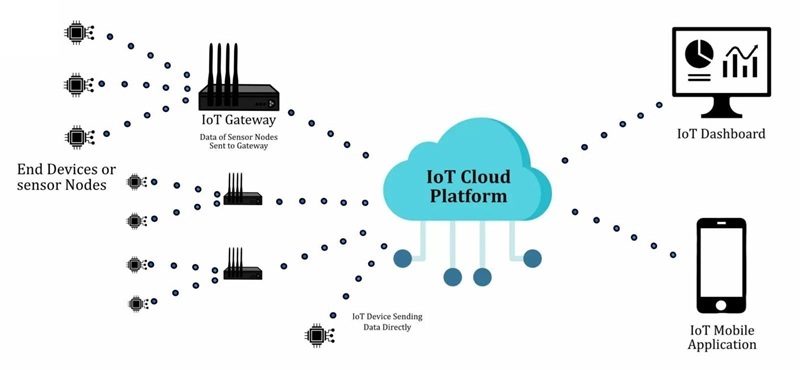
Come funziona un dispositivo IoT
Un prodotto IoT è più facile da comprendere quando viene trattato come un ciclo chiuso e misurabile: osserva il mondo fisico, converte ciò che ha osservato in dati che l'elettronica può gestire, sposta quei dati in un luogo dove possono essere interpretati e poi attiva una risposta. Molti team iniziano a cercare la "connettività", ed è comprensibile, i dimostrazioni sembrano fantastiche quando il cruscotto si aggiorna in tempo reale, ma sul campo, il dispositivo viene giudicato in base a se si comporta allo stesso modo nel giorno 3, giorno 30 e giorno 300.
Il ciclo deve sopravvivere a vincoli quotidiani che tendono a manifestarsi nei momenti peggiori: energia limitata, latenza imprevedibile, interferenze, limiti di costo e aspettative di sicurezza in evoluzione. Quando il ciclo è progettato tenendo presente questi vincoli, i livelli di rete e cloud sembrano un'estensione pulita del prodotto piuttosto che una fonte di sorprese e casi limite fragili.
Sensore: Trasformare un Segnale Fisico in uno Elettrico
All'edge, un sensore converte una variabile del mondo reale in una rappresentazione elettrica che il dispositivo può misurare. La variabile può essere ambientale, meccanica o elettrica, e il compito del sensore è creare un segnale che rimanga interpretabile attraverso variazioni di temperatura, vibrazioni e variabilità di installazione.
Variabili del mondo reale comunemente misurate:
• Temperatura
• Vibrazione
• Pressione
• Luce
• Movimento
• Corrente
• Concentrazione di gas
L'output del sensore di solito rientra in uno dei due gruppi, e la scelta influisce su tutto il resto (progettazione del front-end, campionamento e tolleranza al rumore).
Tipi comuni di output dei sensori:
• Analogico: una tensione o corrente che varia continuamente
• Digitale: letture pacchettizzate su I²C/SPI/UART
Al di fuori delle condizioni di laboratorio, l'accuratezza della misurazione dipende da più del sensore stesso. I fattori di installazione come il posizionamento, la forza di montaggio, il flusso d'aria, le fonti di calore vicine, il routing dei cavi e il accoppiamento meccanico possono influenzare significativamente i risultati.
Gli errori di misurazione sono spesso causati da problemi di installazione piuttosto che da guasti del sensore. Superfici di montaggio flessibili o strutture risonanti possono distorcere i dati e creare letture fuorvianti. Trattare il montaggio e la progettazione meccanica come parte del sistema di misurazione aiuta a ridurre i tempi di risoluzione dei problemi e migliora l'affidabilità delle misurazioni.
Condizione: Front-End Analogico (AFE) e Igiene del Segnale
Molti dispositivi indirizzano gli output raw dei sensori attraverso un front-end analogico (AFE) prima di digitalizzare. Questa fase struttura silenziosamente se il resto del sistema sta lavorando con un segnale stabile e affidabile o con qualcosa che si comporta solo in condizioni controllate.
Funzioni tipiche dell'AFE:
• Biasing e generazione di riferimento per mantenere i segnali all'interno dell'intervallo di ingresso valido dell'ADC
• Amplificazione (amplificatori di strumentazione, stadi di guadagno) per rendere misurabili segnali piccoli
• Filtraggio (passa-basso, filtraggio anti-aliasing) per ridurre il rumore e limitare contenuti ingannevoli ad alta frequenza
• Protezione (strutture ESD, protezione da sovratensioni, morsetti di ingresso) per sopravvivere a errori di cablaggio e manipolazione
Gli ambienti operativi reali spesso introducono sorgenti di rumore come motori, cavi lunghi, regolatori di commutazione e radio vicine. Questi effetti possono creare errori di misurazione che possono sembrare casuali fino a quando non viene identificata la sorgente.
Una buona messa a terra, un'adeguata schermatura e un filtraggio anti-aliasing di base spesso migliorano la qualità del segnale più efficacemente che affidarsi solo a filtraggio software complesso. Affrontare il rumore alla sorgente di solito produce misurazioni e prestazioni di sistema più affidabili.
Convertire: Campionamento ADC con compromessi intenzionali
Quando il segnale è analogico, un ADC lo converte in campioni digitali. La conversione stessa è semplice; ciò che tende a richiedere esperienza è scegliere parametri di campionamento che si comportino bene sotto i limiti reali di batteria e rete.
Due scelte di campionamento che modellano il comportamento a valle:
• Frequenza di campionamento: abbastanza veloce da catturare il fenomeno, ma non così veloce da consumare energia e produrre dati non necessari
• Risoluzione: sufficientemente fine da rilevare cambiamenti significativi senza trasformare rumore e deriva in falsa precisione
Il campionamento funziona meglio quando viene trattato come una decisione a livello di sistema invece di una specifica isolata. Il sovracampionamento può forzare silenziosamente più attività radio (e il tempo radio è spesso ciò che scarica la batteria per primo). Il sotto-campionamento può far perdere eventi brevi ma operativamente significativi, picchi di pressione, impatti, brevi arresti, che gli utenti ricordano perché erano il momento in cui qualcosa è andato storto.
Calcolare: Elaborazione Microcontrollore, Tempistiche e Logica Edge
Un microcontrollore (MCU) legge tipicamente i dati del sensore su un programma disciplinato utilizzando timer, interruzioni e DMA affinché il temporizzatore del dispositivo rimanga coerente anche quando il firmware cresce. Un temporizzatore coerente è uno di quei dettagli che sembra noioso fino al giorno in cui si stai risolvendo un problema sul campo e ti rendi conto che il “segnale” era in realtà jitter di programmazione.
Compiti di elaborazione comuni lato MCU:
• Filtraggio digitale (media mobile, mediana, IIR) per ridurre jitter e valori anomali
• Taratura e compensazione (correzione dell'offset, compensazione della temperatura, linearizzazione)
• Valutazione delle regole (soglie, isteresi, debounce) per prevenire oscillazioni instabili
• Analisi edge leggera (estrazione di caratteristiche, punteggio delle anomalie, compressione) per ridurre larghezza di banda e calcolo su cloud
Un approccio di design utile è separare i dati di misurazione dalla logica decisionale. Le letture dei sensori possono fluttuare a causa di condizioni fisiche normali, mentre un comportamento del sistema stabile può essere mantenuto attraverso isteresi, finestre temporali e controllo a stato. Questa separazione aiuta a ridurre falsi allarmi, migliora la stabilità del sistema e previene indicazioni di guasto errate quando si verificano variazioni temporanee di misurazione.
Non tutte le decisioni traggono beneficio dall'attendere il cloud. Alcune azioni sono sensibili al tempo o orientate all'evitare danni, e spostarle fuori dal dispositivo tende a creare modalità di errore scomode quando la rete è lenta o assente.
Esempi frequentemente gestiti localmente:
• Interruzione da sovracorrente; protezione da surriscaldamento; rilevamento di blocco del motore
Il cloud tende a brillare quando il compito beneficia di un contesto più ampio o di orizzonti temporali più lunghi.
Categorie di decisioni lato cloud:
• Analisi delle tendenze a lungo termine e manutenzione predittiva
• Correlazione tra dispositivi
• Aggiornamenti di modello e modifiche delle politiche a livello di flotta
Una regola pratica su cui i team spesso convergono è semplice: se un comando ritardato potrebbe plausibilmente portare a danni, il dispositivo dovrebbe proteggersi prima e riferire dopo. Questo approccio di solito sembra conservativo in un buon modo, soprattutto quando sei tu ad essere disponibile durante un'interruzione di rete.
Comunicare: Collegamenti Radio/Wired e Protocolli di Applicazione
Lo strato di comunicazione sposta la telemetria su un telefono, gateway o punto finale cloud. Selezionare una tecnologia di collegamento riguarda meno ciò che è di tendenza e più ciò che si adatta all'ambiente fisico, al modello di distribuzione e al budget energetico.
Opzioni di connettività comuni:
• Wi‑Fi; BLE; Zigbee/Thread; cellulare (LTE-M/NB-IoT); Ethernet
Sopra lo strato di collegamento, i dispositivi utilizzano protocolli di applicazione per strutturare e consegnare messaggi. Il protocollo giusto tende a dipendere dal fatto che il prodotto abbia bisogno di telemetria in streaming, flussi di lavoro di configurazione o compatibilità con la plomeria aziendale esistente.
Protocolli di applicazione comuni:
• MQTT
• HTTP
I dispiegamenti reali offrono raramente una connettività stabile. I punti di accesso riavviano, i gateway scompaiono, la copertura cellulare cambia e le interferenze vanno e vengono. I dispositivi sembrano molto più affidabili quando possono memorizzare dati, riprovare con moderazione (non in modo tale da DDOSare la rete) e mantenere un chiaro comportamento dell'ultimo stato noto affinché il sistema rimanga comprensibile quando i collegamenti sono imperfetti.
La telemetria è tipicamente protetta con TLS per riservatezza e integrità. In molti prodotti, la prima vittoria in termini di sicurezza è semplicemente attivare la crittografia ovunque, ma la sicurezza durevole va oltre rendendo la gestione dell'identità e degli aggiornamenti gestibili per l'intera vita del dispositivo.
Blocchi costruttivi di sicurezza comuni:
• Identità uniche dei dispositivi e autenticazione basata su certificato
• Archiviazione sicura delle chiavi (elementi sicuri o zone di fiducia MCU)
• Firmware firmato e avvio sicuro per ridurre il rischio di esecuzione di codice non autorizzato
C'è un modello che i team esperti riconoscono (spesso dopo averlo appreso a proprie spese): il lavoro di sicurezza è molto meno doloroso quando identità, gestione delle chiavi e percorsi di aggiornamento sono progettati in anticipo. Quando quelle basi sono pianificate fin dall'inizio, il dispositivo tende a rimanere utilizzabile per anni, non solo fino al primo aggiornamento importante sul campo.
Cloud e Dati
Nel cloud (o in una piattaforma on-prem), i dati vengono archiviati, spesso in sistemi a serie temporali, quindi aggregati e analizzati. Il cloud è dove la telemetria grezza può essere trasformata in output su cui qualcuno agirà realmente, che si tratti di un utente, di un operatore o di un motore di policy automatizzato.
Output comuni del cloud:
• Avvisi (superamenti delle soglie, rilevamento di guasti)
• Previsioni (vita utile restante, rilevamento di deriva)
• Dashboard (KPI, tendenze, salute della flotta/dispositivo)
• Comandi di controllo (punti di settaggio, programmazioni, abilitare/disabilitare azioni)
Il valore del cloud è più facile da catturare quando i team decidono in anticipo quali decisioni i dati devono supportare. Senza quella disciplina, la telemetria tende a diventare un costoso rumore di fondo, raccolto in modo affidabile, memorizzato diligentemente e poi raramente utilizzato con fiducia.
Attuare: Eseguire Comandi in Sicurezza e in Modo Ripetibile
I comandi inviati di nuovo al dispositivo attivano gli attuatori, e questa parte del ciclo è dove la realtà hardware diventa forte. L'attuazione richiede circuiti di driver abbinati al carico e beneficia di guardrail che rendono i guasti prevedibili piuttosto che caotici.
Attuatori comuni:
• Motori
• Valvole
• Relè
• Riscaldatori
• LED
• Altoparlanti
Elementi comuni di driver e protezione:
• MOSFET; relè; ponti H; triac (a seconda delle caratteristiche del carico)
• Diodi flyback e snubber (per carichi induttivi)
• Rilevamento della corrente e protezioni termiche
• Verifica dello stato quando disponibile (interruttori di fine corsa, feedback sulla posizione, firme elettriche)
Una mentalità di affidabilità che tende a ripagare è assumere che l'attuazione sia dove il rischio si concentra. I sensori spesso falliscono silenziosamente; gli attuatori possono fallire in modi che gli utenti notano immediatamente. Semplici misure di sicurezza, timeout, interblocchi, controlli di sanità, prevengono frequentemente problemi a cascata e fanno sentire il sistema più affidabile durante i necessari casi limite strani.
Il Ciclo Si Ripete
Questo ciclo di sensori; calcolo, comunicazione, attuazione si ripete continuamente. A livello locale, può funzionare in millisecondi; un viaggio di andata e ritorno nel cloud può richiedere secondi a seconda del carico di rete e backend. I buoni prodotti trattano il tempo e la potenza come ingressi di progettazione che modellano ogni altra decisione, piuttosto che come pensieri dopo che devono essere ottimizzati alla fine.
Strategie comuni a livello di sistema:
• Utilizzare l'elaborazione edge per ridurre trasmissioni non necessarie
• Raggruppare e comprimere la telemetria quando la tolleranza alla latenza lo consente
• Dormire aggressivamente e svegliarsi prevedibilmente su dispositivi alimentati a batteria
• Mantenere un "comportamento minimale vitale" anche quando il cloud non può essere raggiunto
Un dispositivo IoT durevole non è definito da un singolo componente. È definito da quanto calma si comporta l'intero ciclo quando la realtà si discosta dal piano: segnali rumorosi, reti intermittenti, hardware invecchiato e comportamento dell'utente imprevedibile. Progettare tenendo presente queste condizioni è spesso la differenza tra una demo che funziona una sola volta e un prodotto che mantiene la propria compostezza anno dopo anno.
Componenti Elettronici sulle Prestazioni dei Dispositivi IoT
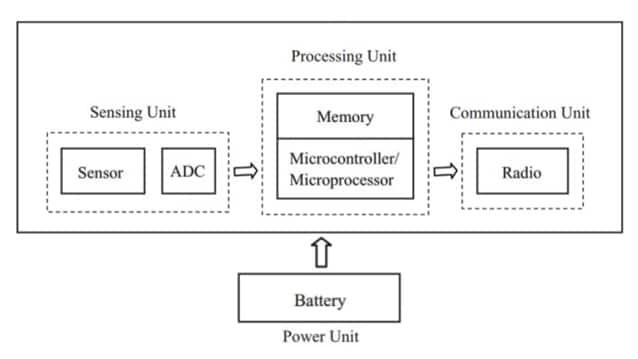
L'hardware IoT tende a sembrare affidabile solo quando gli input dei sensori, il calcolo, lo stoccaggio, la fornitura di energia e la connettività sono modellati come un unico percorso continuo di segnale e potenza.
Una lettura del sensore raramente rimane significativa se la tensione di riferimento cambia, se l'orologio è instabile o se il percorso dei dati occasionalmente perde byte sotto carico. Un collegamento radio raramente rimane utilizzabile se l'alimentazione cala durante le trasmissioni, se l'oscillatore è rumoroso o se la gestione delle credenziali è incoerente tra i riavvii.
Molti team scoprono che l'affidabilità spesso migliora più dalla restrizione dei confini da blocco a blocco piuttosto che dall'aggiunta di un'altra funzionalità: binari prevedibili, tempistiche limitate, accoppiamento del rumore controllato e un comportamento di guasto comprensibile quando qualcosa si rompe.
L'obiettivo del design non è "parti perfette", ma interfacce che si comportano allo stesso modo su un banco di sviluppo, in distribuzioni pilota e mesi dopo sul campo.
Sensore
I sensori convertono le condizioni del mondo reale in segnali elettrici, ma il comportamento del prodotto giorno per giorno è modellato da dettagli che possono sembrare piccoli finché i dati sul campo non li fanno sembrare sgradevolmente grandi.
Rumore, deriva, montaggio, flusso d'aria, condensazione e instradamento dei cavi hanno tutti il modo di trasformare un grafico pulito di laboratorio in distribuzioni disordinate che il firmware deve sopportare.
La gamma e la risoluzione devono adattarsi alla decisione presa, non a una specifica principale. Configurazioni eccessivamente sensibili amplificano spesso il rumore e la deriva, il che tende ad alzare i falsi positivi e aumenta silenziosamente il tempo di calcolo e il tempo di trasmissione radio. Una gamma il più ristretta possibile può sembrare difendibile durante le revisioni di design, eppure il comportamento sul campo favorisce spesso una gamma leggermente più ampia che produce misurazioni più stabili e più interpretabili. Se un modello o una soglia a valle andrà a smussare i dati comunque, spingere la sensibilità grezza troppo oltre può sembrare soddisfacente all'inizio e poi frustrante quando arrivano i ticket di supporto.
La deriva, l'invecchiamento e l'esposizione determinano se le misurazioni rimangono credibili dopo mesi o anni.
La calibrazione generalmente funziona meglio se trattata come una routine del ciclo di vita piuttosto che come un singolo rituale di fabbrica che tutti sperano possa durare per sempre.
• Calibrazione in fabbrica con coefficienti memorizzati.
• Attivatori di rialcalibrazione sul campo (programmati, basati su eventi o assistiti da un tecnico).
• Routine di auto-verifica che segnalano outlier, clipping e saturazione.
I team che mirano a prodotti manutenibili spesso accantonano una quantità modesta di memoria flash e capacità di calcolo per i metadati di calibrazione, la tracciabilità e i controlli di sanità, perché è più economico che spiegare letture incoerenti dopo la distribuzione.
La selezione della frequenza di campionamento di solito diventa una negoziazione tra fisica, batteria e utilità dei dati. Campionare troppo lentamente rischia il fenomeno dell'aliasing e eventi mancati, che possono essere difficili da diagnosticare perché i dati sembrano ancora plausibili. Campionare troppo velocemente aumenta il consumo energetico e il volume dei dati e può creare l'illusione di una migliore comprensione senza migliorare materialmente le decisioni.
Un modello che resiste bene è catturare il fenomeno con un margine sufficiente, filtrare in anticipo (analogico quando aiuta davvero, digitale quando è sufficiente) e ridimensionare per il reporting.
Questo produce spesso risultati migliori in termini di batteria rispetto a un campionamento aggressivo sperando che le analisi in cloud compensino in seguito.
Se un ADC esterno è giustificato di solito dipende da risoluzione, impedenza di ingresso, stabilità di riferimento e tolleranza al rumore. Gli ADC integrati nel MCU spesso funzionano bene per il sensing a medio livello di risoluzione, mentre segnali di precisione tendono a punire scelte di layout e riferimenti casuali.
• Selezione del riferimento a basso rumore e instradamento del riferimento.
• Strategia di messa a terra, tracce di protezione e controllo del percorso di ritorno.
• schermatura e instradamento intenzionale dei cavi vicino ai connettori.
• Protezione ESD collocata dove effettivamente intercetta il transitorio.
Piccole modifiche alla PCB possono ridurre in modo misurabile i jitter e migliorare la ripetibilità, specialmente per fonti ad alta impedenza o segnali analogici a bassa intensità dove "quasi bene" diventa visibilmente instabile nei dati di produzione.
Microcontrollore (MCU)
L'MCU agisce come il centro operativo: legge i sensori tramite GPIO, I²C, SPI e UART; condiziona i segnali; esegue inferenze quando applicabile; gestisce le modalità di alimentazione; e controlla le uscite.
Quando il comportamento dell'MCU è prevedibile, l'intero dispositivo sembra calmo; quando non lo è, i guasti tendono a sembrare casuali anche quando la causa è deterministica.
Un firmware stabile proviene tipicamente da macchine a stati espliciti e tempistiche che hanno confini chiari. I design eventi-driven che utilizzano interruzioni, DMA e timer di solito superano i loop di polling in termini di reattività ed energia, specialmente in dispositivi che vanno spesso in modalità sleep.
Quando i team descrivono blocchi casuali, il colpevole è spesso uno dei pochi recidivi: lavoro illimitato all'interno di un'interruzione, deadlock sul bus condiviso, inversione di priorità o frammentazione della memoria che non è mai stata sottoposta a stress-test durante lunghi periodi di utilizzo.
La pianificazione della RAM e della memoria flash funziona meglio quando include cosa succede dopo il primo successo della demo.
• Buffer di rete e sovraccarico TLS (incluso il comportamento di handshake nel caso peggiore).
• Registrazione, metriche e dump di arresto che gli ingegneri chiederanno in seguito.
• Spazio di staging OTA, più metadati per controlli di integrità.
• Feature creep che arriva prevedibilmente dopo il feedback del pilota.
La memoria sottodimensionata spesso rimane silenziosa all'inizio e poi diventa dolorosa in seguito, proprio quando la diagnostica e la sicurezza degli aggiornamenti diventano gli strumenti principali per controllare il rischio sul campo.
I dispositivi che ci si aspetta siano affidabili di solito beneficiano di avvio sicuro, memorizzazione delle chiavi protette, accelerazione hardware della crittografia e un generatore di numeri casuali vero. Dall'esperienza di distribuzione, i retrofit di sicurezza tendono a risultare scomodi perché si scontrano con i vincoli dell'hardware spedito e le credenziali longeve.
Selezionare un MCU (o aggiungere un elemento sicuro) che supporti l'identità forte e l'avvio misurato riduce spesso la quantità di software intelligente necessaria per compensare le radici di fiducia deboli.
L'accesso per SWD/JTAG e la testabilità pratica di solito decidono se la produzione iniziale è controllata o caotica.
• Pianificazione dell'accesso SWD/JTAG e strategia di blocco per la produzione.
• Punti di test e layout favorevole alle sonde per fissaggi ad alto volume.
• Punti di rilevamento della linea di alimentazione e nodi misurabili per una rapida triage.
Una piccola quantità di infrastruttura di test può risparmiare alle squadre settimane di scomode supposizioni quando il primo grande lotto espone casi limite che non si erano mai presentati su prototipi costruiti a mano.
Moduli di comunicazione
Il modulo di comunicazione plasma più del budget di collegamento: influisce sulla provisioning, sul comportamento degli aggiornamenti, sui flussi di supporto e su un sorprendente numero di modalità di guasto.
Nei dispositivi a batteria, il comportamento radio spesso domina il consumo energetico, quindi le decisioni di connettività tendono a diventare decisioni sulla durata della batteria travestite.
La selezione di solito bilancia portata, latenza, throughput, topologia e budget energetico, con uno sguardo franco all'attrito operativo.
• BLE per collegamenti a corto raggio, a bassa potenza e commissioning dello smartphone.
• Wi‑Fi per un throughput più elevato con corrente di picco più alta e requisiti di integrità energetica più rigorosi.
• Thread/Zigbee per reti mesh e distribuzioni domestiche/industriali a bassa potenza.
• LoRaWAN per lunghe distanze, bassi tassi di dati e rigorosa disciplina del payload.
• LTE‑M/NB‑IoT per copertura a vasta area con vincoli degli operatori e provisioning più complesso.
Le squadre spesso sentono un sollievo una volta che ammettono che “la scelta radio” è inseparabile dalla strategia di ripetizione del firmware, dalla gestione della corrente di picco e dalla pazienza dell'utente durante la configurazione.
Un modulo potente può comunque deludere se l'antenna è mal posizionata, detunata dall'involucro o esposta a ritorni di terra rumorosi.
• Zone di esclusione per l'antenna e routing a impedenza controllata.
• Effetti dell'involucro e test di interazione dell'utente.
• Controlli delle emissioni radiate e probing di suscettibilità.
Quando il margine di collegamento è sottile, le ripetizioni del firmware possono mascherare il sintomo per un po', ma il costo della batteria si accumula in un modo che i team operativi notano molto prima che gli ingegneri lo vedano in laboratorio.
La progettazione della connettività deve sopravvivere ai flussi di lavoro reali piuttosto che a dimostrazioni ideali.
• Provisioning che tollera guasti parziali e comuni errori dell'utente.
• Logica di backoff e retry che evita spirali di drenaggio della batteria auto-inflitte.
• Comportamento di roaming più gestione del ciclo di vita SIM/eSIM per dispositivi cellulari.
• OTA con autenticazione, rollback e programmazione consapevole della larghezza di banda.
Le funzioni OTA funzionano meno come una funzionalità luccicante e più come un canale di manutenzione a lungo termine; quando viene trattato con superficialità, i dispositivi tendono a diventare costosi da supportare, anche se il primo rollout sembra buono.
Gestione dell'energia
La progettazione dell'alimentazione mantiene il dispositivo vivo, ripetibile e noioso, nel miglior senso della parola. Si estende a regolatori, ricarica, misurazione della carica, commutazione del carico e scelte di protezione che devono gestire sia eventi di corrente di picco che aspettative di sonno profondo.
La selezione di buck/boost/LDO beneficia dalla valutazione dell'efficienza su tutto l'intervallo di carico, non solo su un singolo punto di funzionamento. La corrente quiescente in modalità sleep spesso decide se un prodotto soddisfa le aspettative della batteria.
Le radio possono creare picchi di corrente netti; la capacità di bulk, il routing a bassa impedenza e i loop di controllo stabili tendono a decidere se il sistema rimane attivo durante i burst di trasmissione. Molti reset misteriosi finiscono per tornare a fluttuazioni transitorie piuttosto che al firmware, che può essere una lezione umiliante ma utile durante l'integrazione.
La durata della batteria è comunemente vinta durante il sonno, dove piccole perdite si accumulano in perdite misurabili.
• Configurazione di sonno profondo con solo le fonti di rilascio che sono veramente utilizzate.
• RTC o timer a bassa potenza per risvegli periodici.
• Interruzioni GPIO o di sensori per risvegli basati su eventi.
• Power gating per sensori e periferiche che non necessitano di polarizzazione continua.
Misurare il consumo di sonno attualmente su hardware reale, quindi trattare gli aumenti microampere inaspettati come bug, tende a prevenire il lento degrado in cui molti blocchi "quasi spenti" erodono silenziosamente il tempo di funzionamento.
La scelta del circuito integrato di carica dipende dalla chimica, dai limiti termici, dai vincoli normativi e dall'ambiente previsto. La selezione del gauge di carburante dovrebbe riflettere le esigenze di accuratezza attraverso temperatura, carico e invecchiamento. Per le implementazioni all'aperto o non riscaldate, il comportamento a basse temperature spesso diventa il fattore determinante della qualità percepita, quindi soglie di tensione conservative e reportistica onesta della capacità riducono i reclami per spegnimenti improvvisi.
Comportamenti di sovracorrente, sovratensione, polarità inversa e ESD dovrebbero essere considerati come normali condizioni operative per molte implementazioni. Gli ambienti industriali producono comunemente eventi di scarica di cavi e transitori induttivi che possono sembrare "sfortuna" a meno che il design non li anticipi. Clamps appropriati, fusibili, diodi TVS, controllo dell'inrush e decisioni di isolamento spesso decidono se un dispositivo sopravvive al suo primo mese con una reputazione intatta.
Componenti di Archiviazione
L'archiviazione contiene firmware, configurazione, certificati e registri. La scelta tra flash NOR/NAND, EEPROM, FRAM, eMMC o microSD tende a essere guidata da resistenza, prestazioni, costo della distinta materiali e quanto sia problematica una scrittura corrotta dal punto di vista operativo.
I dispositivi reali affrontano cali di tensione, reset del watchdog e scritture parziali.
• Checksum o CRC per configurazione e registri.
• Livellamento dell'usura o frequenza di scrittura limitata per media basati su flash.
• Registrazione in journaling o solo record aggiuntivi per dati che non possono essere scritti a metà.
Un modello operativo frequente è il logging con buffer circolare e velocità di scrittura limitate, che limita il consumo silenzioso della resistenza pur lasciando ancora enough breadcrumb per risolvere problemi sul campo.
Slot firmware A/B più boot verificato e logica di rollback forniscono una rete di sicurezza pratica durante gli aggiornamenti interrotti. Senza queste salvaguardie, una singola perdita di alimentazione durante un aggiornamento può lasciare i dispositivi bloccati sul campo. I prodotti che si scalano senza problemi tendono a trattare la recuperabilità allo stesso livello delle funzionalità di spedizione, perché i costi di supporto tendono a seguire la qualità della storia di recupero.
I certificati e le chiavi dovrebbero essere memorizzati tenendo presente la resistenza alle manomissioni e il controllo degli accessi, non semplicemente da qualche parte non volatile. Anche con una memorizzazione sicura, piani per la rotazione, revoca e risposta agli incidenti riducono l'esposizione a lungo termine quando una credenziale trapela o una flotta è parzialmente compromessa.
Componenti di Interfaccia
LED, display, pulsanti, microfoni, telecamere e sensori biometrici influenzano l'usabilità, ma attirano anche potenza, rischio EMI e considerazioni sulla privacy. Un'interfaccia utente che sembra coerente sotto stress riflette spesso un design elettrico disciplinato più che una lucidatura dell'interfaccia utente.
I pulsanti tendono ad aver bisogno di debouncing e protezione ESD per evitare letture errate sporadiche.
I microfoni e le telecamere tendono a necessitare di rail puliti e messa a terra accurata per evitare artefatti intermittenti che gli utenti interpretano come "difettosi".
• Separazione dei percorsi analogici sensibili da percorsi di commutazione ad alta corrente e RF.
• Pianificazione del percorso di ritorno per limitare il coupling del rumore.
• Scelte di schermatura e filtraggio che corrispondono alla strategia di alloggiamento e cavo.
I fallimenti intermittenti dell'interfaccia utente sono frequentemente causati da accoppiamento da radio o motori, ed è sorprendentemente soddisfacente risolverli con layout e disciplina di messa a terra piuttosto che tramite continui workaround firmware.
I dispositivi si comportano in modo più prevedibile quando hanno una storia offline che non dipende dalla disponibilità della rete.
Un chiaro feedback locale (stati LED univoci e segnalazione di errori minima e accurata) tende a ridurre il carico di supporto e evita la frustrazione dell'utente che deriva dal comportamento di fallimento silenzioso.
Attuatori
Gli attuatori trasformano l'intenzione di controllo in movimento, calore o forza, e di solito richiedono circuiti di interfaccia oltre a un pin MCU diretto. Poiché gli attuatori interagiscono con il mondo fisico, le modalità di guasto tendono a essere visibili, costose ed emotivamente escalatorie per gli utenti. Motori, solenoidi, valvole e relè necessitano comunemente di stadi MOSFET, ponti H o circuiti integrati driver dedicati dimensionati per correnti e transitori reali.
• Diodi flyback o snubber per carichi induttivi.
• Rilevamento di corrente per rilevamento di stallo e risposta a sovraccarichi.
• Considerazioni di design termico per carichi continui o ad alta durata.
L'esperienza sul campo mostra spesso che i problemi legati agli attuatori sono una fonte di guasto frequente, e la derating conservativa più il rilevamento dei guasti tende a migliorare il comportamento della flotta in un modo che i team di supporto notano rapidamente.
Un dispositivo dovrebbe rimanere sicuro quando il firmware va in crash, il cloud è irraggiungibile o i comandi arrivano in ritardo.
• Watchdog e strategia di reset allineati con uscite sicure.
• Stati di uscita di default-sicuri definiti per ogni attuatore e per ogni modalità.
• Posizioni di fail-safe meccanico dove l'applicazione lo richiede.
I progetti più resilienti trattano la perdita di connettività come una normale modalità operativa e definiscono esattamente cosa fa l'attuatore durante quel periodo, in modo che il comportamento rimanga prevedibile anche quando tutto il resto è imperfetto.
Integrazione a Livello di Sistema
I miglioramenti ad alto impatto spesso derivano da pratiche di integrazione che costringono l'intero sistema a dire la verità in anticipo.
• Validazione dell'integrità dell'alimentazione sotto il carico peggiore di radio e attuatore.
• Controllo del rumore attraverso sensori analogici, regolatori di commutazione e driver ad alta corrente.
• Flussi di avvio, aggiornamento e recupero con stati misurabili e chiara osservabilità.
• Test ambientali (temperatura, umidità, vibrazione) scelti per corrispondere alle condizioni di distribuzione effettive.
Quando queste attività vengono trattate come lavoro ingegneristico quotidiano piuttosto che come cerimonia finale, le scelte dei componenti tendono solitamente a diventare meno drammatiche, e il comportamento del dispositivo tende a rimanere consistente dal prototipo alla distribuzione di massa.
Conclusione
I sistemi IoT di successo si basano su un ciclo di dati completo e affidabile che include rilevamento, condizionamento del segnale, elaborazione, comunicazione, sicurezza e gestione dell'energia. Ogni fase influisce sulle prestazioni complessive, sulla durata della batteria, sull'accuratezza e sull'esperienza dell'utente. Bilanciando hardware, firmware, reti e vincoli operativi, i dispositivi IoT possono fornire monitoraggio, controllo e automazione affidabili attraverso una vasta gamma di applicazioni.
Domande Frequenti [FAQ]
1. Perché molti progetti IoT falliscono a causa della qualità della misurazione piuttosto che di problemi di connettività?
La connettività riceve spesso la maggior parte dell'attenzione durante lo sviluppo perché i dashboard e le integrazioni con il cloud sono altamente visibili. Tuttavia, misurazioni imprecise causate da una scarsa posizione dei sensori, vibrazioni, effetti di flusso d'aria, accoppiamento termico, rumore o errori di installazione possono compromettere l'intero sistema. Se i dati originali non sono affidabili, anche le analisi più avanzate, le piattaforme cloud e le reti di comunicazione non possono produrre decisioni affidabili. Il successo a lungo termine dell'IoT in genere inizia con misurazioni stabili piuttosto che con caratteristiche di connettività sofisticate.
2. Perché il montaggio dei sensori dovrebbe essere considerato parte del sistema di rilevamento stesso?
I sensori misurano le condizioni fisiche attraverso la loro interazione con l'ambiente circostante. La forza di montaggio, il design dell'involucro, il cablaggio, il flusso d'aria, il trasferimento di vibrazioni e il contatto termico possono alterare ciò che il sensore percepisce. Un sensore perfettamente calibrato può comunque produrre letture fuorvianti se è montato male. In molte distribuzioni, gli errori legati all'installazione contribuiscono a maggior incertezza delle misurazioni rispetto alle specifiche del sensore stesso, rendendo l'integrazione meccanica una parte critica delle prestazioni complessive del rilevamento.
3. Perché l'oversampling è spesso una minaccia nascosta per la durata della batteria nei dispositivi IoT?
Campionare i dati più frequentemente del necessario aumenta il carico di elaborazione, l'uso della memoria e l'attività di comunicazione. Poiché la trasmissione wireless è frequentemente il maggiore consumatore di energia nei prodotti IoT alimentati a batteria, raccogliere dati eccessivi può aumentare indirettamente l'uso della radio e ridurre l'autonomia. Sebbene alte frequenze di campionamento possano sembrare migliorare l'accuratezza, spesso creano dataset più grandi senza apportare miglioramenti significativi nella qualità delle decisioni. Strategie di campionamento efficaci bilanciano i requisiti di rilevamento degli eventi rispetto al consumo di energia e alle esigenze di segnalazione.
4. Perché i dispositivi IoT di successo separano la logica di misurazione dalla logica di decisione?
I valori dei sensori grezzi fluttuano naturalmente a causa del rumore, della variazione ambientale e del comportamento normale del processo. Se ogni misurazione attiva direttamente un'azione, i sistemi possono diventare instabili e generare falsi allarmi. Separando la raccolta delle misurazioni dalla logica decisionale utilizzando isteresi, macchine a stati, filtri, finestre di temporizzazione e regole di validazione, i dispositivi possono rimanere reattivi evitando reazioni inutili a fluttuazioni temporanee. Questo approccio migliora l'affidabilità e crea un comportamento del sistema più prevedibile in condizioni reali.
5. Perché molte decisioni critiche per l'IoT vengono elaborate localmente anziché essere delegate al cloud?
I sistemi cloud forniscono preziose analisi a lungo termine, gestione della flotta e intuizioni predittive, ma i ritardi di rete e le interruzioni possono renderli inadatti per funzioni di protezione sensibili al tempo. Eventi come condizioni di sovracorrente, surriscaldamento, blocchi del motore o arresti di sicurezza richiedono spesso azioni immediate. Aspettare la conferma del cloud potrebbe consentire il danneggiamento dell'attrezzatura o lo sviluppo di condizioni pericolose. Per questo motivo, le decisioni critiche di protezione e controllo vengono comunemente eseguite al margine mentre le piattaforme cloud si concentrano sul monitoraggio e sull'ottimizzazione.
Blog correlato
-
Quanti zeri in un milione, miliardi di trilioni?
![Quanti zeri in un milione, miliardi di trilioni?]()
29/07/2024
Milioni rappresenta 106, una figura facilmente raggruppabile rispetto agli articoli di tutti i giorni o agli stipendi annuali. Miliardi, equivalenti a... -
Foglio dati MOSFET IRLZ44N, circuito, equivalente, pinout
![Foglio dati MOSFET IRLZ44N, circuito, equivalente, pinout]()
28/08/2024
L'IRLZ44N è un MOSFET di potere N-canale ampiamente utilizzato.Rinomato per le sue eccellenti capacità di commutazione, è molto adatto per numerose... -
Temperatura della batteria troppo bassa, la ricarica si è fermata.Come risolverlo?
![Temperatura della batteria troppo bassa, la ricarica si è fermata.Come risolverlo?]()
06/10/2024
I problemi di ricarica della batteria del telefono cellulare sono comuni ma possono essere gestiti efficacemente.La temperatura svolge un ruolo import... -
BC547 Guida completa del transistor
![BC547 Guida completa del transistor]()
04/07/2024
Il transistor BC547 è comunemente usato in una varietà di applicazioni elettroniche, che vanno dagli amplificatori di segnale di base a circuiti di ... -
Guida completa al SCR (raddrizzatore controllato al silicio)
![Guida completa al SCR (raddrizzatore controllato al silicio)]()
22/04/2024
I rettificatori controllati al silicio (SCR), o tiristi, svolgono un ruolo fondamentale nella tecnologia elettronica di potenza a causa delle loro pre... -
LR621, SR621SW, 364, Equivalenti della batteria AG1 e sostituzioni
![LR621, SR621SW, 364, Equivalenti della batteria AG1 e sostituzioni]()
15/07/2024
Le batterie del pulsante LR621 e SR621SW sono prevalenti in dispositivi elettronici compatti come orologi, piccoli giocattoli, calcolatori e chiavi re... -
Una guida completa ai multiplexer e il loro ruolo nei sistemi digitali
![Una guida completa ai multiplexer e il loro ruolo nei sistemi digitali]()
20/09/2025
I multiplexer sono componenti nei sistemi digitali, progettati per incanalare più segnali di input in una singola linea di output utilizzando segnali... -
Fondamenti di circuiti di amplifica operatoria
![Fondamenti di circuiti di amplifica operatoria]()
28/12/2023
Nell'intricato mondo dell'elettronica, un viaggio nei suoi misteri ci porta invariabilmente a un caleidoscopio di componenti del circuito, sia squisit... -
Confrontare le differenze e le applicazioni di NMOS e PMO
![Confrontare le differenze e le applicazioni di NMOS e PMO]()
15/11/2024
Comprendere le differenze tra i transistor NMOS e PMOS è importante nella progettazione di circuiti efficienti.NMOS (metallo-ossido-semiconduttore di... -
CR2450 vs CR2032 Confronto: tutto ciò che devi sapere
![CR2450 vs CR2032 Confronto: tutto ciò che devi sapere]()
15/09/2025
Batterie per bottoni come CR2450 e CR2032 alimentano molti elettronici quotidiani, da orologi e telecomandi ai dispositivi medici e industriali.Sebben...










Parti calde
- EPM7512AETC144-7
- TAP336K016FCS
- PMB6823RV1.1
- BSH-030-01-L-D-A-TR
- D78214CW
- SP3223EUCA
- C2012NP02W121J060AA
- CS35L19-CWZR
- CL21F335ZPFNNNG
- SKR130/12
- TMS320F28377SPZPS
- MLX90621ESF-BAB-000-TU
- BD6621FP-YE2
- MAX3227EAE+T
- LB1860M-ND-TLM-E
- S2B40-TP
- AT93C46DN-SH-B
- LTST-C191KFKT
- P87LPC767FD
- CGA2B2X8R2A152M050BA
- C0603CH1E220J030BA
- SPV7100E-HLEB2
- 1808SC152KAT3A
- VY1222M47Y5UQ6UV0
- ADS1230IPWR
- SDR7030-220M
- AMS1117-3.3V
- XC7A200T-2FBG676I
- STM32L052T8Y6TR
- 74AUP1T34GW
- QM100E2Y-HK
- SQCSVA0R4BAT1A
- BR24C08FV-E2
- TMS320F28062FPFPQ
- EPF6016ATC144-3
- CGA6M3X7R1H155K200AB
- GJM0335C1E2R0WB01D
- OPA354AIDDAR
- VE-B54-CU
- T491D335M035ZTZ057
- T494B475K025AT
- VI-JW1-CX
- AD8567AR
- XC5204-PQ160AKM
- CF412-PM0379GQ
- DK74HC595S
- NFA81R10C223T1M51-61
- NANDA9R3N4BZBB5F
- PSD3-24-1212
- IGW75N60TG75T60